Learning Goals
After completing this section, you should feel comfortable performing these skills.
- Define the standardized value, or z-score.
- Use technology to convert values into standardized scores.
- Use a dotplot and histogram to identify the number of standard deviations from the mean of certain observations.
- Calculate a value’s standardized score by hand to determine its location relative to the mean.
- Define the Empirical Rule.
Click on a skill above to jump to its location in this section.
In the next activity, you will need to be able to convert values into standardized values (also called standardized scores or z-scores) and use a value’s standardized value to determine whether the value is above, below, or equal to the mean. You will also need to be able to explain the Empirical Rule. In this section, we’ll use a data set to explore how to perform necessary calculations by hand and using technology.
Standardized Values
You learned in Comparing Variability of Data Sets: What to Know that a standard deviation is a measure for how spread out observations are from the mean.
A standardized value, or z-score, is the number of standard deviations an observation is away from the mean.
For example, in this section we will analyze runtimes (in minutes) of G-rated movies to learn how to calculate standardized values. Within this context, the standardized value, or z-score, is the number of standard deviations a particular movie runtime is from the mean.
It is important to note that the distance of a particular movie runtime from the mean is not measured in minutes; rather it is measured in standard deviations. Thus, a z-score of [latex]-2.3[/latex] is an observation that is [latex]2.3[/latex] standard deviations below the mean, and a z-score of [latex]2.3[/latex] is an observation that is [latex]2.3[/latex] standard deviations above the mean. It is important to note that z-scores do not have units associated with them.
Z-Score Formula The value of an observation is standardized using the formula [latex]z=\dfrac{x-\mu}{\sigma}[/latex], where [latex]x[/latex] represents the value of the observation, [latex]\mu[/latex] represents the population mean, [latex]\sigma[/latex] represents the population standard deviation, and [latex]z[/latex] represents the standardized value, or z-score.
Before we use the formula to convert values into standardized values, let’s recap our understanding of standard deviation. In Comparing Variability of Data Sets: What to Know, you learned to understand standard deviation as a measure of variability in a data set. You looked at the statistical components that went into the formulas for standard deviation and variance and saw that larger standard deviations could represent more variability, and vice-versa. We’d like to shift that perspective now and look at a unit of standard deviation as a distance from the mean of a data set in a distribution.
standard deviation as a unit of distance
[Perspective video — a 3-instructor video showing how to think about standard deviation as a unit of distance in a distribution — i.e., illustrating values so many standard deviations above and below the mean of a bell-shaped, unimodal, symmetric distribution. Show how adding or subtracting std devs can obtain a certain value at that location in the distribution. Show that a value’s z-score (negative or positive) is that many std deviations away from the mean in that direction.]
See the example below for a demonstration, then try it out using the Movie Runtimes database to answer the questions below.
inTeractive example
Let’s return again to the data set Sleep Study: Average Sleep, which we used in Comparing Variability of Data Sets: What to Know to learn about standard deviation as a measure of the variability of a data set.
Open the tool at https://dcmathpathways.shinyapps.io/EDA_quantitative/ and select the Sleep Study: Average Sleep data set. Display a histogram and dotplot and make a note of the mean and standard deviation in the descriptive statistics. Round your final answers to the questions below to 3 decimal places, as needed.
- Describe the shape of the data set using the histogram and dotplot. For practice, display a boxplot as well and note the visual clues that you can use to determine the shape of the distribution from the boxplot.
- How does the relationship between the mean and median (given in descriptive statistics) help to support your analysis?
- What are the mean and standard deviation of the data set?
- What number of sleep hours lies one standard deviation above the mean? What value lies one standard deviation below?
- What number of sleep hours lie two standard deviations above and below the mean?
Now it's your turn to try. Let's load the Movie Runtime data set in the technology to calculate the standard deviation of a data set and then convert values to standardized scores by hand.
Go to the Describing and Exploring Quantitative Variables tool at https://dcmathpathways.shinyapps.io/EDA_quantitative/.
Step 1) Select the Single Group tab.
Step 2) Locate the dropdown under Enter Data and select From Textbook.
Step 3) Locate the drop-down menu under Data Set and select Movie Runtime (G Rated 1990-2016).
Step 4) Under Choose Type of Plot, select the options to create a Histogram and a Dotplot of runtime (in minutes).
question 1
question 2
question 3
Use the mean and the standard deviation you entered in Questions 2 and 3 to answer the following questions.
question 4
question 5
Standardizing a Score
At this point, students will be presented with two datasets. They will be able to choose which one they would like to use to answer example questions.
Now that you have obtained the standard deviation of the data set Runtimes using technology, you can calculate any observation's z-score to locate it in the data set relative to the mean.
calculating z-scores
[Worked example video - a 3-instructor video that works through an example like questions 6 - 9]
interactive Example
Recall, to calculate a z-score given an observation, use the formula [latex]z=\dfrac{x-\mu}{\sigma}[/latex], where [latex]x[/latex] represents the value of the observation, [latex]\mu[/latex] represents the population mean, [latex]\sigma[/latex] represents the population standard deviation, and [latex]z[/latex] represents the standardized value, or z-score.
We'll use data set Sleep Study: Average Sleep, you saw in Comparing Variability of Data Sets: What to Know to demonstrate how to calculate z-scores for individual observations in the data set. The mean [latex]\mu[/latex] and standard deviation [latex]\sigma[/latex] in the formula represent the population the sample came from. Since we don't know these, we'll use the sample mean and standard deviation in our calculations.
The mean of the data is 7.97 hours with a standard deviation of 0.965. Calculate the z-scores for each of the following observations and indicate if the given value lies above or below the mean. Round your calculations to two decimal places.
- [latex]6.93\text{ hours}[/latex]
- [latex]9.87\text{ hours}[/latex]
- [latex]7.97\text{ hours}[/latex]
- [latex]4.95\text{ hours}[/latex]
Use the mean and the standard deviation you calculated in Questions 2 and 3 to answer Questions 6 - 9.
question 6
question 7
question 8
question 9
The Empirical Rule
If a distribution is bell shaped, unimodal, and symmetric, then we can estimate how many observations are within a certain number of standard deviations. The Empirical Rule (also known as the [latex]68-95-99.7[/latex] rule) is a guideline that predicts the percentage of observations within a certain number of standard deviations.
the empirical rule
[insert a video describing (but not using) the Empirical Rule]-->this video could be good, but she refers back to other lessons and writes on the diagram in a way that could be confusing (calculating half of 68% and not others, uses x bar and s instead of mu and sigma, writes 99.7% on the outside of the bell while the others are clearly written inside). She begins an example at 4:41.
The Empirical Rule states that:
- about [latex]68[/latex]% of observations in a data set will be within one standard deviation of the mean.
- about [latex]95[/latex]% of the observations in a data set will be within two standard deviations of the mean.
- about [latex]99.7[/latex]% of the observations in a data set will be within three standard deviations of the mean.
Graphically, the Empirical Rule can be expressed like this:
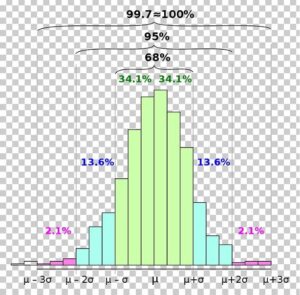
Fill in the blank for each of Questions 10 - 12
question 10
question 11
question 12
Summary
In this section, you've seen how to convert observed values into standardized scores (z-scores) and that the value of the z-score gives meaningful information about the location of the observation with respect to the mean of a data set. You also seen how to explain what the Empirical Rule is. Let's summarize where these skills showed up in the material.
- In question 1 - 5, you converted values into standardized scores.
- In Questions 6 - 9, you used a value's standardized score to determine whether the value is above, below, or equal to the mean.
- In Questions 10 - 12, you explained the Empirical Rule.
Being able to calculate z-scores and understanding the Empirical Rule will be necessary for completing the next activity. If you feel comfortable with these skills, it's time to move on!
