Learning outcomes
- Recognize when to use a hypothesis test or a confidence interval to draw a conclusion about a population mean.
- Under appropriate conditions, conduct a hypothesis test about a population mean. State a conclusion in context.
- Under appropriate conditions, conduct a hypothesis test about a mean for a matched pairs design. State a conclusion in context.
- Interpret the P-value as a conditional probability.
Introduction
We did hypothesis tests in earlier modules. But we will see that the steps and the logic of the hypothesis test are the same. Before we get into the details, let’s practice identifying research questions and studies that involve a population mean.
NOTE: In this section, you will see a simulation referenced. We will not use the simulation to calculate p-values, instead we will use the T.DIST function in Excel. The tcdf function can also be used on the TI 83/84 calculators.
Try It
Example
Cell Phone Data
Cell phones and cell phone plans can be very expensive, so consumers must think carefully when choosing a cell phone and service. This decision is as much about choosing the right cellular company as it is about choosing the right phone. Many people use the data/Internet capabilities of a phone as much as, if not more than, they use voice capability. The data service of a cell company is therefore an important factor in this decision. In the following example, a student named Melanie from Los Angeles applies what she learned in her statistics class to help her make a decision about buying a data plan for her smartphone.
Melanie read an advertisement from the Cell Phone Giants (CPG, for short, and yes, we’re using a fictitious company name) that she thinks is too good to be true. The CPG ad states that customers in Los Angeles get average data download speeds of 4 Mbps. With this speed, the ad claims, it takes, on average, only 12 seconds to download a typical 3-minute song from iTunes.
Only 12 seconds on average to download a 3-minute song from iTunes! Melanie has her doubts about this claim, so she gathers data to test it. She asks a friend who uses the CPG plan to download a song, and it takes 13 seconds to download a 3-minute song using the CPG network. Melanie decides to gather more evidence. She uses her friend’s phone and times the download of the same 3-minute song from various locations in Los Angeles. She gets a mean download time of 13.5 seconds for her sample of downloads.
What can Melanie conclude? Her sample has a mean download time that is greater than 12 seconds. Isn’t this evidence that the CPG claim is wrong? Why is a hypothesis test necessary? Isn’t the conclusion clear?
Let’s review the reason Melanie needs to do a hypothesis test before she can reach a conclusion.
Why should Melanie do a hypothesis test?
Melanie’s data (with a mean of 13.5 seconds) suggest that the average download time overall is greater than the 12 seconds claimed by the manufacturer. But wait. We know that samples will vary. If the CPG claim is correct, we don’t expect all samples to have a mean download time exactly equal to 12 seconds. There will be variability in the sample means. But if the overall average download time is 12 seconds, how much variability in sample means do we expect to see? We need to determine if the difference Melanie observed can be explained by chance.
We have to judge Melanie’s data against random samples that come from a population with a mean of 12. For this reason, we must do a simulation or use a mathematical model to examine the sampling distribution of sample means. Based on the sampling distribution, we ask, Is it likely that the samples will have mean download times that are greater than 13.5 seconds if the overall mean is 12 seconds? This probability (the P-value) determines whether Melanie’s data provides convincing evidence against the CPG claim.
Now let’s do the hypothesis test.
Step 1: Determine the hypotheses.
As always, hypotheses come from the research question. The null hypothesis is a hypothesis that the population mean equals a specific value. The alternative hypothesis reflects our claim. The alternative hypothesis says the population mean is “greater than” or “less than” or “not equal to” the value we assume is true in the null hypothesis.
Melanie’s hypotheses:
- H0: It takes 12 seconds on average to download Melanie’s song from iTunes with the CPG network in Los Angeles.
- Ha: It takes more than 12 seconds on average to download Melanie’s song from iTunes using the CPG network in Los Angeles.
We can write the hypotheses in terms of µ. When we do so, we should always define µ. Here μ = the average number of seconds it takes to download Melanie’s song on the CPG network in Los Angeles.
- H0: μ = 12
- Ha: μ > 12
Step 2: Collect the data.
To conduct a hypothesis test, Melanie knows she has to use a t-model of the sampling distribution since the population standard deviation is unknown. She thinks ahead to the conditions required, which helps her collect a useful sample.
Recall the conditions for use of a t-model.
- There is no reason to think the download times are normally distributed (they might be, but this isn’t something Melanie could know for sure). So the sample has to be large (more than 30).
- The sample has to be random. Melanie decides to use one phone but randomly selects days, times, and locations in Los Angeles.
Melanie collects a random sample of 45 downloads by using her friend’s phone to download her song from iTunes according to the randomly selected days, times, and locations.
Melanie’s sample of size 45 downloads has an average download time of 13.5 seconds. The standard deviation for the sample is 3.2 seconds. Now Melanie needs to determine how unlikely this data is if CPG’s claim is actually true.
Step 3: Assess the evidence.
Assuming the average download time for Melanie’s song is really 12 seconds, what is the probability that 45 random downloads of this song will have a mean of 13.5 seconds or more?
This is a question about sampling variability. Melanie must determine the standard error. She knows the standard error of random sample means is [latex]\sigma \text{}/\sqrt{n}[/latex]. Since she has no way of knowing the population standard deviation, σ, Melanie uses the sample standard deviation, s = 3.2, as an approximation. Therefore, Melanie approximates the standard error of all sample means (n = 45) to be
[latex]s\text{}/\sqrt{n}\text{}=\text{}3.2\text{}/\sqrt{45}\text{}=\text{}0.48[/latex]
Now she can assess how far away her sample is from the claimed mean in terms of standard errors. That is, she can compute the t-score of her sample mean.
[latex]T\text{}=\text{}\frac{\mathrm{statistic}-\mathrm{parameter}}{\mathrm{standard}\text{}\mathrm{error}}\text{}=\text{}\frac{\stackrel{¯}{x}-μ}{s\text{}/\sqrt{n}}\text{}=\text{}\frac{13.5-12}{0.48}\text{}=\text{}3.14[/latex]
The sample mean for Melanie’s random sample is approximately 3.14 standard errors above the overall mean of 12. We know from previous experience that a sample mean this far above µ is very unlikely. With a t-score this large, the P-value is very small. We use a simulation of the t-model for 44 degrees of freedom to verify this.

We want the probability that the sample mean is greater than 13.5. This corresponds to the probability that T is greater than 3.14. The P-value is 0.0015. (In Excel, use =1-T.DIST(3.14, 44, 1) = 0.0015)
Step 4: State a conclusion.
Here the logic is the same as for other hypothesis tests. We use the P-value to make a decision. The P-value helps us determine if the difference we see between the data and the hypothesized value of µ is statistically significant or due to chance. One of two outcomes can occur:
- One possibility is that results similar to the actual sample are extremely unlikely. This means the data does not fit with results from random samples selected from the population described by the null hypothesis. In this case, it is unlikely that the data came from this population. The probability as measured by the P-value is small, so we view this as strong evidence against the null hypothesis. We reject the null hypothesis in favor of the alternative hypothesis.
- The other possibility is that results similar to the actual sample are fairly likely (not unusual). This means the data fits with typical results from random samples selected from the population described by the null hypothesis. The probability as measured by the P-value is large. In this case, we do not have evidence against the null hypothesis, so we cannot reject it in favor of the alternative hypothesis.
Melanie’s data is very unlikely if µ = 12. The probability is essentially zero (P-value = 0.0015). This means we will rarely see sample means greater than 13.5 if µ = 12. So we reject the null and conclude the alternative hypothesis. In other words, this sample provides strong evidence that CPG has overstated the speed of its data download capability.
The following activities give you an opportunity to practice parts of the hypothesis testing process for a population mean. Later you will have the opportunity to practice the hypothesis test from start to finish.
Try It
For the following scenarios, give the null and alternative hypotheses and state in words what µ represents in your hypotheses. A good definition of µ describes both the variable and the population.
Comment
In the previous example, Melanie did not state a significance level for her test. If she had, the logic is the same as we used for hypothesis tests in Modules 8 and 9. To come to a conclusion about H0, we compare the P-value to the significance level α.
- If P ≤ α, we reject H0. We conclude there is significant evidence in favor of Ha.
- If P > α, we fail to reject H0. We conclude the sample does not provide significant evidence in favor of Ha.
Try It
Try It
Try It
More on Checking Conditions for a T-Test
In practice, you will often see the use of a t-test with small samples. Technically, we can use the t-test with small samples only if we know the variable has a normal distribution in the population. But this is hard to verify. In addition, no variable has a perfect normal distribution. So what does the requirement that the “variable be normally distributed in the population” really mean?
We call a confidence interval or a hypothesis test robust if the confidence level or P-value does not change very much when the conditions for use of the procedure are not met.
T-procedures are robust when the variable is not normally distributed in the population, as long as the distribution is not heavily skewed. But how can we determine if the distribution of the variable in the population is heavily skewed? In this introductory course, we examine the distribution of the variable in the sample and make an educated guess about what is going on in the population.
Now we investigate this question: Can we tell from a sample whether the variable is normally distributed in the population?
Example
Variable Skewed in the Population
Let’s start with a skewed distribution in the population. Can we tell that this distribution is not normal by looking at random samples?
The following figure shows the monthly payment on first home mortgages for 5,000 people, as reported in the 2000 U.S. Census. Think of this as data from the population of a small town. From this population, we randomly selected 20 people. We did this three times. Notice that for each random sample, the shape of the distribution of the monthly payments in the sample is skewed to the right, just like the distribution in the population. In 2 of the 3 samples, we also see outliers, just as we see in the population. So by looking at the sample, we can get a pretty good sense that the variable is not normally distributed in the population.
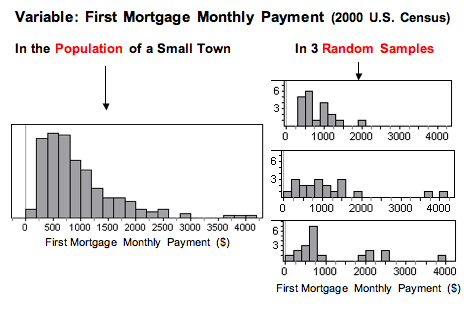
In this example, the sample size is less than 30. We can use the t-test only if the variable is normally distributed in the population. The shape of the distribution in any one of these samples suggests that the variable has a skewed distribution in the population, so we would not conduct a t-test with any of these samples.
Example
Variable Normal in the Population
Now we look at a variable that has an approximately normal distribution in the population. Can we tell that this distribution is approximately normal by looking at random samples?
The following graphs show the heights (in centimeters) of 5,000 women. Think of this as data from the population of a small town. From this population, we randomly selected 20 women. We did this three times. Notice that for each random sample, the shape of the distribution of the heights in the sample is not skewed, and there are no outliers. By looking at the sample, we can get a pretty good sense that the variable is not skewed in the population, which suggests that the variable may be somewhat normally distributed in the population.
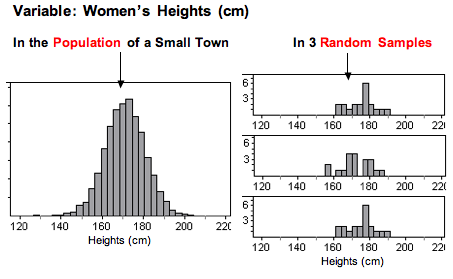
In this example, the sample size is less than 30. We can only use the t-test if the variable is normally distributed in the population. The shape of the distribution in any one of these samples indicates that the variable does not have a skewed distribution in the population, suggesting that the distribution in the population is somewhat normal. Since the t-procedures are robust, we would conduct a t-test with any of these samples.
What’s the Main Point?
We previously stated the conditions for use of the t-procedures as follows:
(1) If the variable is normally distributed in the population, you can always use the t-procedures.
(2) If the variable is not normally distributed in the population (or you can’t determine this factor), the sample size must be greater than 30 for safe use of the t-procedures.
We are now loosening these conditions somewhat because the t-procedures are robust.
(3) If the sample is small (n ≤ 30), plot the data. If the distribution in the sample is not heavily skewed and does not have outliers, then we assume the variable is somewhat normally distributed in the population, so we use t-procedures.
Comment
If we use a t-procedure for a small sample (n ≤ 30), it is good practice to include a disclaimer with the conclusion. We might say something like, “On the basis of the sample, we are assuming that the variable is distributed without strong skew or extreme outliers in the population. The conclusion from this test is valid only if this assumption is true.”
Try It
Each histogram in the following questions represents a random sample. We do not know if the variable has a normal distribution in the population, but we want to run a t-test to test a claim about the population mean. For each histogram, choose the option that best describes how to proceed with the hypothesis test.
Comment
Recall that the sample mean and standard deviation are not resistant to outliers. An outlier in the data can make the mean and standard deviation poor measures of center and spread. So why can we use data from large samples even if the data has an outlier? Well, if the sample is large enough, the distribution of sample means will still be approximately normal. And the t-model will be a good fit when we estimate the standard error of the sample means using the sample standard deviation. This is the important point. The P-value and confidence level come from a model of the sampling distribution, not from a model of the population’s distribution.
Summary in a Diagram
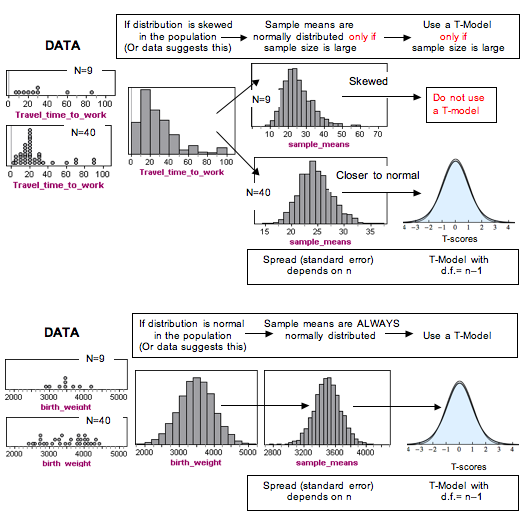
We finish our discussion of the hypothesis test for a population mean with a review of the meaning of the P-value, along with a review of type I and type II errors.
Review of the Meaning of the P-value
At this point, we assume you know how to use a P-value to make a decision in a hypothesis test. The logic is always the same. If we pick a level of significance (α), then we compare the P-value to α.
- If the P-value ≤ α, reject the null hypothesis. The data supports the alternative hypothesis.
- If the P-value > α, do not reject the null hypothesis. The data is not strong enough to support the alternative hypothesis.
In fact, we find that we treat these as “rules” and apply them without thinking about what the P-value means. So let’s pause here and review the meaning of the P-value, since it is the connection between probability and decision-making in inference.
Summary of Requirements:
- The sample is a simple random sample.
- Either the sample size is at least 30 (n > 30) or the sample is from a normally distributed population.
Example
Birth Weights in a Town
Suppose that babies in the town had a mean birth weight of 3,500 grams in 2010. This year, a random sample of 50 babies has a mean weight of about 3,400 grams with a standard deviation of about 500 grams. Here is the distribution of birth weights in the sample.
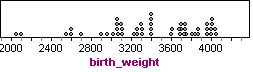
Obviously, this sample weighs less on average than the population of babies in the town in 2010. A decrease in the town’s mean birth weight could indicate a decline in overall health of the town. But does this sample give strong evidence that the town’s mean birth weight is less than 3,500 grams this year?
We now know how to answer this question with a hypothesis test. Let’s use a significance level of 5%.
Let μ = mean birth weight in the town this year. The null hypothesis says there is “no change from 2010.”
- H0: μ < 3,500
- Ha: μ = 3,500
Since the sample is large, we can conduct the T-test (without worrying about the shape of the distribution of birth weights for individual babies.)
[latex]T\text{}=\text{}\frac{\mathrm{3,400}-\mathrm{3,500}}{\frac{500}{\sqrt{50}}}\text{}\approx \text{}-1.41[/latex]
Statistical software tells us the P-value is 0.082 = 8.2%. (In Excel, =T.DIST(-1.41, 49, 1) = 0.082). Since the P-value is greater than 0.05, we fail to reject the null hypothesis.
Our conclusion: This sample does not suggest that the mean birth weight this year is less than 3,500 grams (P-value = 0.082). The sample from this year has a mean of 3,400 grams, which is 100 grams lower than the mean in 2010. But this difference is not statistically significant. It can be explained by the chance fluctuation we expect to see in random sampling.
What Does the P-Value of 0.082 Tell Us?
A simulation can help us understand the P-value. In a simulation, we assume that the population mean is 3,500 grams. This is the null hypothesis. We assume the null hypothesis is true and select 1,000 random samples from a population with a mean of 3,500 grams. The mean of the sampling distribution is at 3,500 (as predicted by the null hypothesis.) We see this in the simulated sampling distribution.
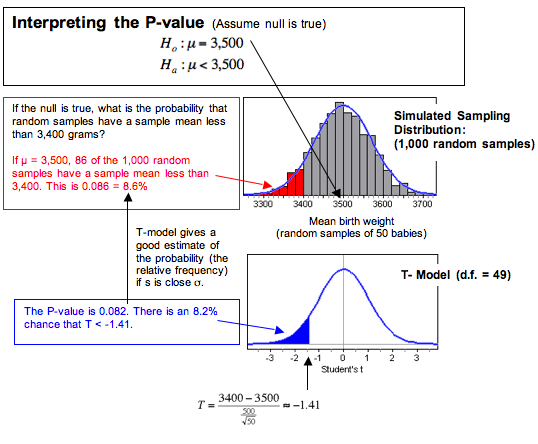
In the simulation, we can see that about 8.6% of the samples have a mean less than 3,400. Since probability is the relative frequency of an event in the long run, we say there is an 8.6% chance that a random sample of 500 babies has a mean less than 3,400 if the population mean is 3,500. We can see that the corresponding area to the left of T = −1.41 in the T-model (with df = 49) also gives us a good estimate of the probability. This area is the P-value, about 8.2%.
If we generalize this statement, we say the P-value is the probability that random samples have results more extreme than the data if the null hypothesis is true. (By more extreme, we mean further from value of the parameter, in the direction of the alternative hypothesis.) We can also describe the P-value in terms of T-scores. The P-value is the probability that the test statistic from a random sample has a value more extreme than that associated with the data if the null hypothesis is true.
Try It
What Does a P-Value Mean?
Do women who smoke run the risk of shorter pregnancy and premature birth? The mean pregnancy length is 266 days. We test the following hypotheses.
- H0: μ = 266
- Ha: μ < 266
Suppose a random sample of 40 women who smoke during their pregnancy have a mean pregnancy length of 260 days with a standard deviation of 21 days. The P-value is 0.04.
What probability does the P-value of 0.04 describe? Label each of the following interpretations as valid or invalid.
Review of Type I and Type II Errors
We know that statistical inference is based on probability, so there is always some chance of making a wrong decision. Recall that there are two types of wrong decisions that can be made in hypothesis testing. When we reject a null hypothesis that is true, we commit a type I error. When we fail to reject a null hypothesis that is false, we commit a type II error.
The following table summarizes the logic behind type I and type II errors.

It is possible to have some influence over the likelihoods of committing these errors. But decreasing the chance of a type I error increases the chance of a type II error. We have to decide which error is more serious for a given situation. Sometimes a type I error is more serious. Other times a type II error is more serious. Sometimes neither is serious.
Recall that if the null hypothesis is true, the probability of committing a type I error is α. Why is this? Well, when we choose a level of significance (α), we are choosing a benchmark for rejecting the null hypothesis. If the null hypothesis is true, then the probability that we will reject a true null hypothesis is α. So the smaller α is, the smaller the probability of a type I error.
It is more complicated to calculate the probability of a type II error. The best way to reduce the probability of a type II error is to increase the sample size. But once the sample size is set, larger values of α will decrease the probability of a type II error (while increasing the probability of a type I error).
General Guidelines for Choosing a Level of Significance
- If the consequences of a type I error are more serious, choose a small level of significance (α).
- If the consequences of a type II error are more serious, choose a larger level of significance (α). But remember that the level of significance is the probability of committing a type I error.
- In general, we pick the largest level of significance that we can tolerate as the chance of a type I error.
Try It
Let’s return to the investigation of the impact of smoking on pregnancy length.
Recap of the hypothesis test: The mean human pregnancy length is 266 days. We test the following hypotheses.
- H0: μ = 266
- Ha: μ < 266
Let’s Summarize
In this “Hypothesis Test for a Population Mean,” we looked at the four steps of a hypothesis test as they relate to a claim about a population mean.
Step 1: Determine the hypotheses.
- The hypotheses are claims about the population mean, µ.
- The null hypothesis is a hypothesis that the mean equals a specific value, µ0.
- The alternative hypothesis is the competing claim that µ is less than, greater than, or not equal to the [latex]{\mathrm{μ}}_{0}[/latex] .
- When [latex]{H}_{a}[/latex] is [latex]μ[/latex] < [latex]{μ}_{0}[/latex] or [latex]μ[/latex] > [latex]{μ}_{0}[/latex] , the test is a one-tailed test.
- When [latex]{H}_{a}[/latex] is [latex]μ[/latex] ≠ [latex]{μ}_{0}[/latex] , the test is a two-tailed test.
Step 2: Collect the data.
Since the hypothesis test is based on probability, random selection or assignment is essential in data production. Additionally, we need to check whether the t-model is a good fit for the sampling distribution of sample means. To use the t-model, the variable must be normally distributed in the population or the sample size must be more than 30. In practice, it is often impossible to verify that the variable is normally distributed in the population. If this is the case and the sample size is not more than 30, researchers often use the t-model if the sample is not strongly skewed and does not have outliers.
Step 3: Assess the evidence.
- If a t-model is appropriate, determine the t-test statistic for the data’s sample mean.
[latex]t = \frac{\mathrm{sample}\text{ }\mathrm{mean }-\mathrm{ population}\text{ }\mathrm{mean}}{\mathrm{estimated }\text{ }\mathrm{standard }\text{ }\mathrm{error }}\text{ }=\text{}\frac{\bar{x} - μ}{\frac{s}{\sqrt{n}}}[/latex]
- Use the test statistic, together with the alternative hypothesis, to determine the P-value. (If the t-model is appropriate, we use the T.DIST function in Excel to calculate the p-value.)
- The P-value is the probability of finding a random sample with a mean at least as extreme as our sample mean, assuming that the null hypothesis is true.
- As in all hypothesis tests, if the alternative hypothesis is greater than, the P-value is the area to the right of the test statistic. If the alternative hypothesis is less than, the P-value is the area to the left of the test statistic. If the alternative hypothesis is not equal to, the P-value is equal to double the tail area beyond the test statistic.
Step 4: Give the conclusion.
The logic of the hypothesis test is always the same. To state a conclusion about H0, we compare the P-value to the significance level, α.
- If P ≤ α, we reject H0. We conclude there is significant evidence in favor of Ha.
- If P > α, we fail to reject H0. We conclude the sample does not provide significant evidence in favor of Ha.
- We write the conclusion in the context of the research question. Our conclusion is usually a statement about the alternative hypothesis (we accept Ha or fail to acceptHa) and should include the P-value.
Other Hypothesis Testing Notes
- Remember that the P-value is the probability of seeing a sample mean at least as extreme as the one from the data if the null hypothesis is true. The probability is about the random sample; it is not a “chance” statement about the null or alternative hypothesis.
- Hypothesis tests are based on probability, so there is always a chance that the data has led us to make an error.
- If our test results in rejecting a null hypothesis that is actually true, then it is called a type I error.
- If our test results in failing to reject a null hypothesis that is actually false, then it is called a type II error.
- If rejecting a null hypothesis would be very expensive, controversial, or dangerous, then we really want to avoid a type I error. In this case, we would set a strict significance level (a small value of α, such as 0.01).
- Finally, remember the phrase “garbage in, garbage out.” If the data collection methods are poor, then the results of a hypothesis test are meaningless.
For information about t-tests for matched-pairs problems, see Appendix J.