Learning Outcomes
- Calculate standard deviation for a set of data using technology
An important characteristic of any set of data is the variation in the data. In some data sets, the data values are concentrated closely near the mean; in other data sets, the data values are more widely spread out from the mean. The most common measure of variation, or spread, is the standard deviation. The standard deviation is a number that measures how far data values are from their mean.
The standard deviation provides a numerical measure of the overall amount of variation in a data set, and can be used to determine whether a particular data value is close to or far from the mean.
The standard deviation
- provides a measure of the overall variation in a data set, and
- can be used to determine whether a particular data value is close to or far from the mean.
The standard deviation provides a measure of the overall variation in a data set
The standard deviation is always positive or zero. The standard deviation is small when the data are all concentrated close to the mean, exhibiting little variation or spread. The standard deviation is larger when the data values are more spread out from the mean, exhibiting more variation.
Suppose that we are studying the amount of time customers wait in line at the checkout at supermarket [latex]A[/latex] and supermarket [latex]B[/latex]. The average wait time at both supermarkets is five minutes. At supermarket [latex]A[/latex], the standard deviation for the wait time is two minutes; at supermarket [latex]B[/latex] the standard deviation for the wait time is four minutes.
Because supermarket [latex]B[/latex] has a higher standard deviation, we know that there is more variation in the wait times at supermarket [latex]B[/latex]. Overall, wait times at supermarket [latex]B[/latex] are more spread out from the average; wait times at supermarket [latex]A[/latex] are more concentrated near the average.
The standard deviation can be used to determine whether a data value is close to or far from the mean
Suppose that Rosa and Binh both shop at supermarket [latex]A[/latex]. Rosa waits at the checkout counter for seven minutes and Binh waits for one minute. At supermarket [latex]A[/latex], the mean waiting time is five minutes and the standard deviation is two minutes. The standard deviation can be used to determine whether a data value is close to or far from the mean.
Rosa waits for seven minutes:
- Seven is two minutes longer than the average of five; two minutes is equal to one standard deviation.
- Rosa’s wait time of seven minutes is two minutes longer than the average of five minutes.
- Rosa’s wait time of seven minutes is one standard deviation above the average of five minutes.
Binh waits for one minute.
- One is four minutes less than the average of five; four minutes is equal to two standard deviations.
- Binh’s wait time of one minute is four minutes less than the average of five minutes.
- Binh’s wait time of one minute is two standard deviations below the average of five minutes.
- A data value that is two standard deviations from the average is just on the borderline for what many statisticians would consider to be far from the average. Considering data to be far from the mean if it is more than two standard deviations away is more of an approximate “rule of thumb” than a rigid rule. In general, the shape of the distribution of the data affects how much of the data is further away than two standard deviations. (You will learn more about this in later chapters.)
The number line may help you understand standard deviation. If we were to put five and seven on a number line, seven is to the right of five. We say, then, that seven is one standard deviation to the right of five because [latex]5 + (1)(2) = 7[/latex].
If one were also part of the data set, then one is two standard deviations to the left of five because [latex]5 + (–2)(2) = 1[/latex].

- In general, a value = mean + (#ofSTDEV)(standard deviation)
- Where #ofSTDEVs = the number of standard deviations
- #ofSTDEV does not need to be an integer
- One is two standard deviations less than the mean of five because: [latex]1 = 5 + (–2)(2)[/latex]
The equation value = mean + (#ofSTDEVs)(standard deviation) can be expressed for a sample and for a population.
- Sample: [latex]\displaystyle{x}=\overline{{x}}+[/latex](# of STDEV)[latex]{({s})}[/latex]
- Population: [latex]\displaystyle{x}=\mu+[/latex](# of STDEV)[latex]{(\sigma)}[/latex]
The lower case letter [latex]s[/latex] represents the sample standard deviation and the Greek letter [latex]σ[/latex] (sigma, lower case) represents the population standard deviation.
The symbol [latex]\displaystyle\overline{{x}}[/latex] is the sample mean and the Greek symbol [latex]μ[/latex] is the population mean.
Recall: Finding the Distance Between TWo Points
To calculate the distance between two points on a number line, take the larger number and subtract the smaller number. When you think about numbers on a number line, zero is in the middle and the numbers to the left are negative and the numbers to the right are positive. The negative numbers are below zero and the positive numbers are above zero. Distance measures how far apart two numbers are from each other, therefore it is always positive. If you calculate a negative distance, that only means the direction of the distance.
Calculating the Standard Deviation
If [latex]x[/latex] is a number, then the difference “[latex]x[/latex] – mean” is called its deviation. In a data set, there are as many deviations as there are items in the data set. The deviations are used to calculate the standard deviation. If the numbers belong to a population, in symbols a deviation is [latex]x – μ[/latex]. For sample data, in symbols a deviation is [latex]\displaystyle{x}-\overline{{x}}[/latex].
The procedure to calculate the standard deviation depends on whether the numbers are the entire population or are data from a sample. The calculations are similar, but not identical. Therefore, the symbol used to represent the standard deviation depends on whether it is calculated from a population or a sample. The lower case letter [latex]s[/latex] represents the sample standard deviation and the Greek letter [latex]σ[/latex] (sigma, lower case) represents the population standard deviation. If the sample has the same characteristics as the population, then [latex]s[/latex] should be a good estimate of [latex]σ[/latex].
To calculate the standard deviation, we need to calculate the variance first. The variance is the average of the squares of the deviations (the [latex]x[/latex] – [latex]\displaystyle\overline{{x}}[/latex] values for a sample, or the [latex]x – μ[/latex] values for a population). The symbol [latex]σ^2[/latex] represents the population variance; the population standard deviation [latex]σ[/latex] is the square root of the population variance. The symbol [latex]s^2[/latex] represents the sample variance; the sample standard deviation [latex]s[/latex] is the square root of the sample variance. You can think of the standard deviation as a special average of the deviations.
If the numbers come from a census of the entire population and not a sample, when we calculate the average of the squared deviations to find the variance, we divide by [latex]N[/latex], the number of items in the population. If the data are from a sample rather than a population, when we calculate the average of the squared deviations, we divide by [latex]n – 1[/latex], one less than the number of items in the sample.
In the following video an example of calculating the variance and standard deviation of a set of data is presented.
Recall: Exponential Notation
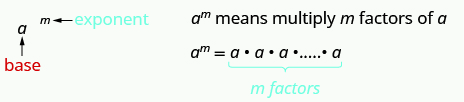
This is read [latex]a[/latex] to the [latex]{m}^{\mathrm{th}}[/latex] power.
Recall: Exponential Notation
The symbol for the square root is called a radical symbol and looks like this: [latex]\sqrt{\,\,\,}[/latex]. The expression [latex]\sqrt{25}[/latex] is read “the square root of twenty-five” or “radical twenty-five.” The number that is written under the radical symbol is called the radicand.
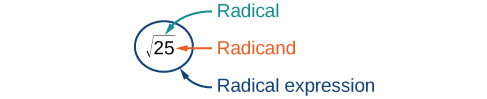
The square root of a square
For a nonnegative real number, a, [latex]\sqrt{a^2}=a[/latex]
The radicand represents the same number being multiplied to itself. For example, for [latex]\sqrt{25} = \sqrt{5 \cdot 5} = 5[/latex].
Formulas for the Sample Standard Deviation
[latex]\displaystyle{s}=\sqrt{{\frac{{\sum{({x}-\overline{{x}})}^{{2}}}}{{{n}-{1}}}}}{\quad\text{or}\quad}{s}=\sqrt{{\frac{{\sum{f{{({x}-\overline{{x}})}}}^{{2}}}}{{{n}-{1}}}}}[/latex]
For the sample standard deviation, the denominator is [latex]n – 1[/latex], that is the sample size MINUS [latex]1[/latex].
Formulas for the Population Standard Deviation
[latex]\displaystyle\sigma=\sqrt{{\frac{{\sum{({x}-\mu)}^{{2}}}}{{{N}}}}}{\quad\text{or}\quad}\sigma=\sqrt{{\frac{{\sum{f{{({x}-\mu)}}}^{{2}}}}{{{N}}}}}[/latex]
For the population standard deviation, the denominator is [latex]N[/latex], the number of items in the population.
In these formulas, [latex]f[/latex] represents the frequency with which a value appears. For example, if a value appears once, [latex]f[/latex] is one. If a value appears three times in the data set or population, [latex]f[/latex] is three.
Sampling Variability of a Statistic
The statistic of a sampling distribution was discussed in Descriptive Statistics: Measuring the Center of the Data. How much the statistic varies from one sample to another is known as the sampling variability of a statistic. You typically measure the sampling variability of a statistic by its standard error. The standard error of the mean is an example of a standard error. It is a special standard deviation and is known as the standard deviation of the sampling distribution of the mean. You will cover the standard error of the mean when you learn about The Central Limit Theorem (not now). The notation for the standard error of the mean is [latex]\displaystyle\frac{{\sigma}}{{\sqrt{n}}}[/latex] where [latex]σ[/latex] is the standard deviation of the population and [latex]n[/latex] is the size of the sample.
Note
In practice, use a calculator or computer software to calculate the standard deviation. If you are using a TI-83, 83+, 84+ calculator, you need to select the appropriate standard deviation [latex]σ_x[/latex] or [latex]s_x[/latex] from the summary statistics. We will concentrate on using and interpreting the information that the standard deviation gives us. However you should study the following step-by-step example to help you understand how the standard deviation measures variation from the mean. (The calculator instructions appear at the end of this example.)
Example
In a fifth grade class, the teacher was interested in the average age and the sample standard deviation of the ages of her students. The following data are the ages for a sample of [latex]n = 20[/latex] fifth grade students. The ages are rounded to the nearest half year:
[latex]\displaystyle {9; 9.5; 9.5; 10; 10; 10; 10; 10.5; 10.5; 10.5; 10.5; 11; 11; 11; 11; 11; 11; 11.5; 11.5; 11.5;}[/latex]
Solution:
[latex]\displaystyle\overline{x} = \frac{9+9.5(2)+10(4)+10.5(4)+11(6)+11.5(3)}{20}={10.525}[/latex]
The average age is [latex]10.53[/latex] years, rounded to two places.
The variance may be calculated by using a table. Then the standard deviation is calculated by taking the square root of the variance. We will explain the parts of the table after calculating [latex]s[/latex].
| Data | Freq. | Deviations | [latex]Deviations^2[/latex] | (Freq.)( [latex]Deviations^2[/latex]) |
|---|---|---|---|---|
| [latex]x[/latex] | [latex]f[/latex] | ( [latex]x[/latex] – [latex]\displaystyle\overline{x}[/latex]) | ( [latex]x[/latex] –[latex]\displaystyle\overline{x}[/latex])2 | ( [latex]f[/latex])([latex]x[/latex] –[latex]\displaystyle\overline{x}[/latex])2 |
| [latex]9[/latex] | [latex]1[/latex] | [latex]9 – 10.525 = –1.525[/latex] | [latex](–1.525)^2 = 2.325625[/latex] | [latex]1 × 2.325625 = 2.325625[/latex] |
| [latex]9.5[/latex] | [latex]2[/latex] | [latex]9.5 – 10.525 = –1.025[/latex] | [latex](–1.025)^2 = 1.050625[/latex] | [latex]2 × 1.050625 = 2.101250[/latex] |
| [latex]10[/latex] | [latex]4[/latex] | [latex]10 – 10.525 = –0.525[/latex] | [latex](–0.525)^2 = 0.275625[/latex] | [latex]4 × 0.275625 = 1.1025[/latex] |
| [latex]10.5[/latex] | [latex]4[/latex] | [latex]10.5 – 10.525 = –0.025[/latex] | [latex](–0.025)^2 = 0.000625[/latex] | [latex]4 × 0.000625 = 0.0025[/latex] |
| [latex]11[/latex] | [latex]6[/latex] | [latex]11 – 10.525 = 0.475[/latex] | [latex](0.475)^2 = 0.225625[/latex] | [latex]6 × 0.225625 = 1.35375[/latex] |
| [latex]11.5[/latex] | [latex]3[/latex] | [latex]11.5 – 10.525 = 0.975[/latex] | [latex](0.975)^2 = 0.950625[/latex] | [latex]3 × 0.950625 = 2.851875[/latex] |
| The total is [latex]9.7375[/latex] |
The sample variance, [latex]\displaystyle{s}^{2}[/latex], is equal to the sum of the last column [latex](9.7375)[/latex] divided by the total number of data values minus one [latex](20 – 1)[/latex]:
[latex]s^2 =\frac{9.7375}{20-1} =0.5125[/latex]
The sample standard deviation [latex]s[/latex] is equal to the square root of the sample variance: [latex]s = \sqrt{0.5125} = 0.715891[/latex] which is rounded to two decimal places, [latex]s[/latex] = 0.72.
Typically, you do the calculation for the standard deviation on your calculator or computer. The intermediate results are not rounded. This is done for accuracy.
- For the following problems, recall that value = mean + (#ofSTDEVs)(standard deviation). Verify the mean and standard deviation or a calculator or computer.
- For a sample: [latex]x[/latex] =[latex]\displaystyle\overline{x}[/latex] + (#ofSTDEVs)([latex]s[/latex])
- For a population: [latex]x[/latex] = [latex]μ[/latex] + (#ofSTDEVs)([latex]σ[/latex])
- For this example, use [latex]x[/latex] =[latex]\displaystyle\overline{x}[/latex] + (#ofSTDEVs)([latex]s[/latex]) because the data is from a sample
- Verify the mean and standard deviation on your calculator or computer.
- Find the value that is one standard deviation above the mean. Find ([latex]\displaystyle\overline{x}[/latex]+ [latex]1s[/latex]).
- Find the value that is two standard deviations below the mean. Find ([latex]\displaystyle\overline{x}[/latex] – [latex]2s[/latex]).
- Find the values that are [latex]1.5[/latex] standard deviations from (below and above) the mean.
Try It
On a baseball team, the ages of each of the players are as follows:
[latex]\displaystyle {21; 21; 22; 23; 24; 24; 25; 25; 28; 29; 29; 31; 32; 33; 33; 34; 35; 36; 36; 36; 36; 38; 38; 38; 40}[/latex]
Use your calculator or computer to find the mean and standard deviation. Then find the value that is two standard deviations above the mean.
Explanation of the Standard Deviation Calculation Shown in the Table
The deviations show how spread out the data are about the mean. The data value [latex]11.5[/latex] is farther from the mean than is the data value [latex]11[/latex] which is indicated by the deviations [latex]0.97[/latex] and [latex]0.47[/latex]. A positive deviation occurs when the data value is greater than the mean, whereas a negative deviation occurs when the data value is less than the mean. The deviation is [latex]–1.525[/latex] for the data value nine. If you add the deviations, the sum is always zero. (For Example 1, there are [latex]n = 20[/latex] deviations.) So you cannot simply add the deviations to get the spread of the data. By squaring the deviations, you make them positive numbers, and the sum will also be positive. The variance, then, is the average squared deviation.
The variance is a squared measure and does not have the same units as the data. Taking the square root solves the problem. The standard deviation measures the spread in the same units as the data.
Notice that instead of dividing by [latex]n= 20[/latex], the calculation divided by [latex]n – 1 = 20 – 1 = 19[/latex] because the data is a sample. For the sample variance, we divide by the sample size minus one ([latex]n – 1[/latex]). Why not divide by [latex]n[/latex]? The answer has to do with the population variance. The sample variance is an estimate of the population variance. Based on the theoretical mathematics that lies behind these calculations, dividing by ([latex]n – 1[/latex]) gives a better estimate of the population variance.
Note
Your concentration should be on what the standard deviation tells us about the data. The standard deviation is a number which measures how far the data are spread from the mean. Let a calculator or computer do the arithmetic.
The standard deviation, [latex]s[/latex] or [latex]σ[/latex], is either zero or larger than zero. When the standard deviation is zero, there is no spread; that is, the all the data values are equal to each other. The standard deviation is small when the data are all concentrated close to the mean, and is larger when the data values show more variation from the mean. When the standard deviation is a lot larger than zero, the data values are very spread out about the mean; outliers can make [latex]s[/latex] or [latex]σ[/latex] very large.
The standard deviation, when first presented, can seem unclear. By graphing your data, you can get a better “feel” for the deviations and the standard deviation. You will find that in symmetrical distributions, the standard deviation can be very helpful but in skewed distributions, the standard deviation may not be much help. The reason is that the two sides of a skewed distribution have different spreads. In a skewed distribution, it is better to look at the first quartile, the median, the third quartile, the smallest value, and the largest value. Because numbers can be confusing, always graph your data. Display your data in a histogram or a box plot.
Example
Use the following data (first exam scores) from Susan Dean’s spring pre-calculus class:
[latex]\displaystyle {33; 42; 49; 49; 53; 55; 55; 61; 63; 67; 68; 68; 69; 69; 72; 73; 74; 78; 80; 83; 88; 88; 88; 90; 92; 94; 94; 94; 94; 96; 100}[/latex]
- Create a chart containing the data, frequencies, relative frequencies, and cumulative relative frequencies to three decimal places.
- Calculate the following to one decimal place using a TI-83+ or TI-84 calculator:
- The sample mean
- The sample standard deviation
- The median
- The first quartile
- The third quartile
- [latex]IQR[/latex]
- Construct a box plot and a histogram on the same set of axes. Make comments about the box plot, the histogram, and the chart.

Try It
The following data show the different types of pet food stores in the area carry.
[latex]\displaystyle {6; 6; 6; 6; 7; 7; 7; 7; 7; 8; 9; 9; 9; 9; 10; 10; 10; 10; 10; 11; 11; 11; 11; 12; 12; 12; 12; 12; 12;}[/latex]
Calculate the sample mean and the sample standard deviation to one decimal place using a TI-83+ or TI-84 calculator.
Standard Deviation of Grouped Frequency Tables
Recall that for grouped data we do not know individual data values, so we cannot describe the typical value of the data with precision. In other words, we cannot find the exact mean, median, or mode. We can, however, determine the best estimate of the measures of center by finding the mean of the grouped data with the formula:
Mean of Frequency Table =[latex]\displaystyle\frac{{\sum(fm)}}{{\sum(f)}}[/latex]
where [latex]f[/latex] = interval frequencies and [latex]m[/latex] = interval midpoints.
Just as we could not find the exact mean, neither can we find the exact standard deviation. Remember that standard deviation describes numerically the expected deviation a data value has from the mean. In simple English, the standard deviation allows us to compare how “unusual” individual data is compared to the mean.
Example
Find the standard deviation for the data in the table below.
| Class | Frequency, [latex]f[/latex] | Midpoint, [latex]m[/latex] | [latex]m^2[/latex] | [latex]\displaystyle\overline{x}^2[/latex] | [latex]fm^2[/latex] | Standard Deviation |
|---|---|---|---|---|---|---|
| [latex]0–2[/latex] | [latex]1[/latex] | [latex]1[/latex] | [latex]1[/latex] | [latex]7.58[/latex] | [latex]1[/latex] | [latex]3.5[/latex] |
| [latex]3–5[/latex] | [latex]6[/latex] | [latex]4[/latex] | [latex]16[/latex] | [latex]7.58[/latex] | [latex]96[/latex] | [latex]3.5[/latex] |
| [latex]6–8[/latex] | [latex]10[/latex] | [latex]7[/latex] | [latex]49[/latex] | [latex]7.58[/latex] | [latex]490[/latex] | [latex]3.5[/latex] |
| [latex]9–11[/latex] | [latex]7[/latex] | [latex]10[/latex] | [latex]100[/latex] | [latex]7.58[/latex] | [latex]700[/latex] | [latex]3.5[/latex] |
| [latex]12–14[/latex] | [latex]0[/latex] | [latex]13[/latex] | [latex]169[/latex] | [latex]7.58[/latex] | [latex]0[/latex] | [latex]3.5[/latex] |
| [latex]15–17[/latex] | [latex]2[/latex] | [latex]16[/latex] | [latex]256[/latex] | [latex]7.58[/latex] | [latex]512[/latex] | [latex]3.5[/latex] |
For this data set, we have the mean, [latex]\displaystyle\overline{x}[/latex] = [latex]7.58[/latex] and the standard deviation, [latex]\displaystyle{s}_{x} = 3.5[/latex]. This means that a randomly selected data value would be expected to be [latex]3.5[/latex] units from the mean. If we look at the first class, we see that the class midpoint is equal to one. This is almost two full standard deviations from the mean since [latex]7.58 – 3.5 – 3.5 = 0.58[/latex]. While the formula for calculating the standard deviation is not complicated, [latex]\displaystyle{s}_{x}=\sqrt{{\frac{{f{(m-\overline{x})}^{2}}}{{n-1}}}}[/latex] where [latex]\displaystyle{s}_{x} =[/latex]sample standard deviation, [latex]\displaystyle\overline{x}[/latex] = sample mean, the calculations are tedious. It is usually best to use technology when performing the calculations.
Try It
Find the standard deviation for the data from the previous example
| Class | Frequency, [latex]f[/latex] |
|---|---|
| [latex]0–2[/latex] | [latex]1[/latex] |
| [latex]3–5[/latex] | [latex]6[/latex] |
| [latex]6–8[/latex] | [latex]10[/latex] |
| [latex]9–11[/latex] | [latex]7[/latex] |
| [latex]12–14[/latex] | [latex]0[/latex] |
| [latex]15–17[/latex] | [latex]2[/latex] |
First, press the STAT key and select 1:Edit

Input the midpoint values into L1 and the frequencies into L2

Select STAT, CALC, and 1: 1-Var Stats

Select 2nd then 1 then , 2nd then 2Enter

You will see displayed both a population standard deviation, σ_x, and the sample standard deviation, [latex]s_x[/latex].
Candela Citations
- Revision and Adaptation. Provided by: Lumen Learning. License: CC BY: Attribution
- OpenStax Statistics. Located at: https://openstax.org/books/statistics/pages/1-introduction. License: CC BY: Attribution. License Terms: Access for free at https://openstax.org/books/statistics/pages/1-introduction
- Introductory Statistics. Authored by: Barbara Illowsky, Susan Dean. Provided by: Open Stax. Located at: https://openstax.org/books/introductory-statistics/pages/1-introduction. License: CC BY: Attribution. License Terms: Access for free at https://openstax.org/books/introductory-statistics/pages/1-introduction
- Unit 11: Exponents and Polynomials, from Developmental Math: An Open Program. Provided by: Monterey Institute of Technology and Education. Located at: http://nrocnetwork.org/resources/downloads/nroc-math-open-textbook-units-1-12-pdf-and-word-formats/. License: CC BY: Attribution
- Unit 16: Radical Expressions and Quadratic Equations, from Developmental Math: An Open Program. Provided by: Monterey Institute of Technology and Education. Located at: http://nrocnetwork.org/resources/downloads/nroc-math-open-textbook-units-1-12-pdf-and-word-formats/. License: CC BY: Attribution
- How to calculate Standard Deviation and Variance. Authored by: statisticsfun. Located at: https://youtu.be/qqOyy_NjflU. License: All Rights Reserved. License Terms: Standard YouTube License
