How can probability help us understand the likelihood of an event?
Before we begin studying probability topics, it is helpful to consider how it relates to the work we have already done. In previous modules, we stated the difference between quantitative and categorical variables:
- Quantitative variables have numeric values that can be averaged. A quantitative variable is frequently a measurement—for example, a person’s height in inches.
- Categorical variables are variables that can have one of a limited number of values, or labels. Values that can be represented by categorical variables include, for example, a person’s eye color, gender, or home state; a vehicle’s body style (sedan, SUV, minivan, etc.); a dog’s breed (bulldog, greyhound, beagle, etc.).
The module Descriptive Statistics focused on describing the overall pattern (shape, center, and spread) of the distribution of a quantitative variable. Now, in this module, we will study the relationship between two categorical variables. As we organize and analyze data from two categorical variables, we make extensive use of contingency tables, tree diagrams and Venn diagrams. By using these tools, we will investigate probabilities of events that are independent, events that are dependent and events that can happen at the same time.
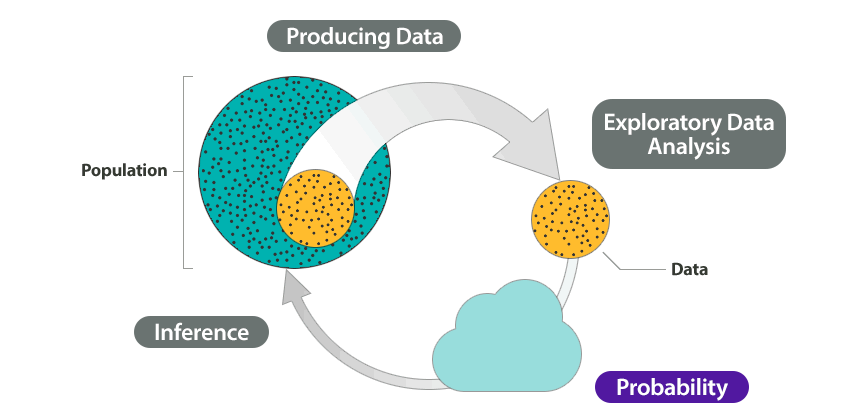
Understanding probability will help us interpret the likelihood of observing data under specific assumptions about a population. The probabilities that are calculated will then allow us to make inferences about the population.
Candela Citations
- Provided by: Lumen Learning. License: CC BY: Attribution
- Concepts in Statistics. Provided by: Open Learning Initiative. Located at: http://oli.cmu.edu. License: CC BY: Attribution
