What can we conclude from data?
To understand how to organize data, we need to understand what kind of data is gathered. For example, data that is gathered about temperatures are numbers. Data based on numbers or quantitative data, like temperature, allows us to conduct certain kinds of analyses, as opposed to gathered data that answers a Yes/No question. Knowing what kind of data are gathered is critical to making correct numerical summaries, such as averages and percentages. Knowing what kind of data are gathered is also necessary for creating correct graphical representations of the data. Creating graphs and numerical summaries about data are known as descriptive statistics.
If data is selected in such a way that it is representative of a population, then conclusions can be drawn about the population. If the data comes from a well-designed experiment, then conclusions can be drawn about cause and effect. Both types of conclusions are known as inferential statistics. Of course, we need a sample that represents the population well. This involves careful planning but also involves chance. For example, if our goal is to determine the percentage of U.S. adults who favor the death penalty, we do not want our sample to contain only Democrats or only Republicans. We can give everyone the same opportunity to be in the sample, but we will let chance select the sample.
For a well-designed experiment, we would want to use chance to assign subjects to treatments, instead of allowing people to choose what treatment to receive. For example, we would not want to let patients choose whether to receive an investigational medication or a traditional medication. If this was done, the sicker patients might choose the investigational medication. This would mean that we would not know how the medication works on all patients with the particular illness.
The main goal of any statistical study is to answer a question about a population based on a sample. Of course, samples will vary due to chance, and we will need to answer our question in spite of this variability. We need to understand how sample results will vary and how sample results relate to the population as a whole when chance is involved. This is where probability comes in. The example that follows shows the entire process of a statistical study, from stating a research question to drawing a conclusion about the population.
Example – The big picture of statistics
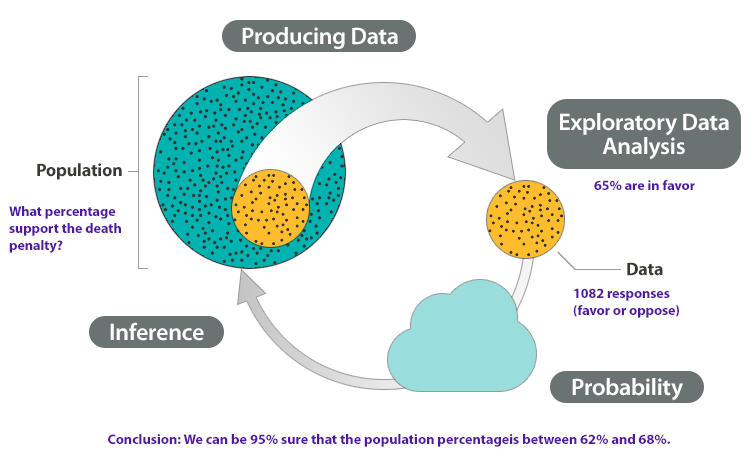
At the end of April 2005, ABC News and the Washington Post conducted a poll to determine the percentage of U.S. adults who support the death penalty.
Research question: What percentage of U.S. adults support the death penalty?
Steps in the statistical investigation:
- Produce Data: Determine what to measure, then collect the data.
The poll selected 1,082 U.S. adults at random. Each adult answered this question: “Do you favor or oppose the death penalty for a person convicted of murder?” - Explore the Data: Analyze and summarize the data.
In the sample, 65% favored the death penalty. - Draw a Conclusion: Use the data, probability, and statistical inference to draw a conclusion about the population.
Our goal is to determine the percentage of the U.S. adult population that supports the death penalty. We know that different samples will give different results. What are the chances that our sample reflects the opinions of the population within 3%? Probability describes the likelihood that our sample is this accurate. So we can say with 95% confidence that between 62% and 68% of the population favor the death penalty.
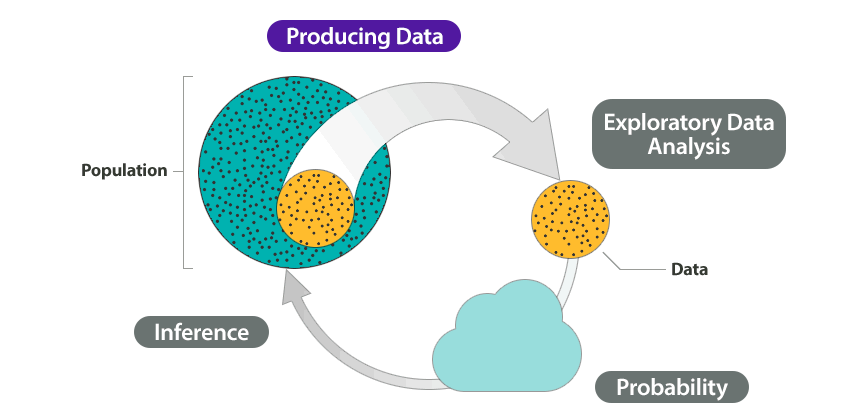
Let’s Summarize
A statistical investigation begins with a research question. Then the investigation proceeds with the following steps:
- Produce Data: Determine what to measure, then collect the data.
- Explore the Data: Analyze and summarize the data (also called exploratory data analysis).
- Draw a Conclusion: Use the data, probability, and statistical inference to draw a conclusion about the population.
Types of Statistical Studies and Producing Data
In this first module, we focus on the “produce data” step in a statistical investigation, focusing on randomization in data collection, and what is meant by a well-designed experiment. We also begin to look at some of the exploratory data analysis techniques, including numerical summaries for data and graphs.
Candela Citations
- Provided by: Lumen Learning. License: CC BY: Attribution
- Concepts in Statistics. Provided by: Open Learning Initiative. Located at: http://oli.cmu.edu. License: CC BY: Attribution
