goals for this section
After completing this section, you should feel comfortable performing these skills.
- Define the terms: first quartile, third quartile, interquartile range, and five-number summary.
- Identify the features of a boxplot
- Calculate interquartile range for a dataset.
- Calculate the range of observations characterized as upper outliers or lower outliers.
- Interpret the features of a boxplot.
- Use a boxplot of a dataset to identify whether the shape of its distribution is left-skewed, symmetric, or right-skewed.
Click on a skill above to jump to its location in this section.
Boxplots are helpful for visualizing the distribution of a quantitative variable. A boxplot clearly shows the median of the data and provides a summary at a glance of the bulk of the data and the presence of outliers. In the next activity, you will need to be able to identity and interpret the features of a boxplot, identify outliers in a dataset, and relate a boxplot of a quantitative variable to its distribution. In this section, you’ll learn to identify the key pieces of information needed to accomplish these tasks.
Features of a Boxplot
In order to interpret boxplots, you will need to identify the minimum, maximum, and median of a quantitative variable. You’ve done this in previous activities. If you need a refresher, take a look at the video below. A boxplot captures only the median of the dataset, not the mean, as a measure of center.
recall
Core skill:
Five-Number Summary
You will also need to know the following definitions:
- the first quartile of a quantitative variable (sometimes denoted Q1) is the value below which one quarter of the data lies, and the first quartile is also equal to the 25th percentile;
- the third quartile of a quantitative variable (sometimes denoted Q3) is the value below which three quarters of the data lay, and the third quartile is also equal to the 75th percentile; and
- the interquartile range (sometimes denoted IQR) of a quantitative variable is the quantity Q3–Q1.
The collection of the minimum, first quartile, median, third quartile, and maximum form the five-number summary of the variable.
first and third quartiles
[Perspective video — a 3 instructor video showing how to understand Q1 and Q3 as percentiles and/or quarters of data. See below for the idea:]
- the location of the Q1/25th percentile and Q3/75th percentile on a number line along with other percentile locations such as 10th and 98th along with three ways to think about it:
- 1) “if a student scores in the 10th percentile of a test like the SAT, they have scored higher than only 10% of all the test takers but if they score in the 98th percentile, then their score is higher than 98% of all the test takers.” and
- 2) “percentiles divide data into two parts — the lower part (she scored higher than 98% of the test takers) and the higher part (2% of the test takers scored higher than she did)” and 3) “the 25th percentile (first quartile) splits the data into the lower 25% and the 75% above that; the 50th percentile (2nd quartile) splits the data in half (marked by the median); the 75th percentile (3rd quartile)splits the data into the lower 75% and the 25% of the data above that.”
- 3) Subtracting the value of Q1 from the value of Q3 gives the IQR (the distance between the 25th percentile and the 75th percentile)
- (critics may point out that students will have seen all of this before, which is true but doesn’t acknowledge that students also need a brief refresher at this point.)
Identifying the Features of a Boxplot
As we explore the features of boxplots, we will work with part of a dataset that reports information about whether drivers involved in a fatal crash were impaired by alcohol.[1] The dataset contains 51 entries corresponding to all 50 states, as well as Washington, DC.
The following table gives the five-number summary for the percentage of drivers involved in fatal collisions who were alcohol-impaired in all 50 states and Washington, DC.
| Minimum | First Quartile | Median | Third Quartile | Maximum |
| 16 | 28 | 30 | 33 | 44 |
One of the ways to visualize the data using the five-number summary is by creating a boxplot. For questions 1 – 4, refer to the following boxplot, which depicts data about the percentage of drivers involved in fatal collisions who were alcohol-impaired in all 50 states and Washington, DC. The boxplot is superimposed with the letters A – G labeling different features of the plot.
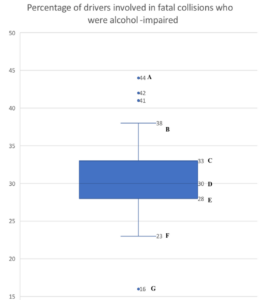
question 1
Match the labeled feature on the above boxplot to the term that describes it.
| Term | Boxplot Feature |
| Minimum | |
| First quartile (Q1) | |
| Median | |
| Third quartile (Q3) | |
| Maximum |
For questions 2 -4, complete each sentence using information from the boxplot above.
question 2
In about half of the states, fewer than _______ of drivers involved in a fatal crash were impaired by alcohol.
a) 23%
b) 28%
c) 30%
d) 33%
e) 38%
f) 44%
question 3
In about one quarter of the states, fewer than _______ of drivers involved in a fatal crash were impaired by alcohol.
a) 23%
b) 28%
c) 30%
d) 33%
e) 38%
f) 44%
question 4
_______ of the states had alcohol involved in 33% or more of their fatal crashes.
a) One-fourth
b) One half
c) Three-fourths
Interquartile Range and Outliers
Now, let’s define the idea of an outlier more precisely. Previously, we’ve seen that an outlier is a value that is unusual, given the other values in a dataset. But what does “unusual” mean? To be more precise, for data with only one variable, let’s define the define the following:
- upper outlier as an observation that is greater than Q3 + 1.5 × (IQR); and
- lower outlier as an observation that is less than Q1 – 1.5 × (IQR).
Use these definitions with the boxplot above question 1 to complete the sentences in questions 5 and 6.
identifying features of a boxplot
[Worked example – a 3-instructor video showing a worked example similar to Questions 5 – 7]
question 5
The interquartile range (IQR) of this dataset is ______.
question 6
Recall that we say that upper outliers lie above Q3 + 1.5 × (IQR), and lower outliers lie below Q1 – 1.5 × (IQR). Because of this, states with more than ________% of fatal crashes involving alcohol impairment are considered upper outliers, and states with fewer than ________% of fatal crashes involving alcohol impairment are considered lower outliers.
question 7
Again, referring to the boxplot above Question 1, we saw previously how some of the boxplot’s features relate to the five-number summary, but when outliers are present, the boxplot is modified as shown below. On the following table, match the labeled feature on the boxplot to the term that describes it.
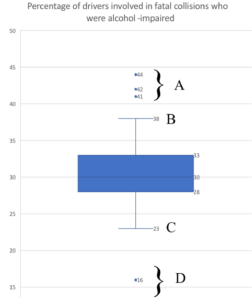
| Term | Boxplot Feature |
| Upper outlier(s) | |
| Lower outlier(s) | |
| Greatest value of an observation that is not an upper outlier | |
| Lowest value of an observation that is not a lower outlier |
It’s important to note that there are several good methods to use for determining an observation to be an outlier in the distribution. The IQR method commonly uses a distance 1.5 times IQR from Q1 or Q3, but certain applications use larger distances. The IQR method does work for skewed distributions, though. In the next section, you’ll learn about another method that doesn’t involve the IQR, and which works well for symmetrical distributions. Depending upon the application, it may be desirable to set the distance 2 or even 3 times IQR, but 1.5 times is commonly used and works well for our application, so we use it here.
Interpreting the Features of a Boxplot
The following table lists each state in the dataset, along with the corresponding percentages of drivers involved in fatal crashes who were impaired by alcohol, in order from lowest percentage to highest percentage. Use this table and the definition of outlier to answer questions 8 -9.
| Drivers Involved in Fatal Crashes by State | |||
| State | Percentage of Drivers Involved in Fatal Crashes and Impaired by Alcohol | State | Percentage of Drivers Involved in Fatal Crashes and Impaired by Alcohol |
| Utah | 16 | Maine | 30 |
| Kentucky | 23 | New Hampshire | 30 |
| Kansas | 24 | Vermont | 30 |
| Alaska | 25 | Mississippi | 31 |
| Georgia | 25 | North Carolina | 31 |
| Iowa | 25 | Pennsylvania | 31 |
| Arkansas | 26 | Maryland | 32 |
| Oregon | 26 | Nevada | 32 |
| District of Columbia | 27 | Wyoming | 32 |
| New Mexico | 27 | Louisiana | 33 |
| Virginia | 27 | South Dakota | 33 |
| Arizona | 28 | Washington | 33 |
| California | 28 | Wisconsin | 33 |
| Colorado | 28 | Illinois | 34 |
| Michigan | 28 | Missouri | 34 |
| New Jersey | 28 | Ohio | 34 |
| West Virginia | 28 | Massachusetts | 35 |
| Florida | 29 | Nebraska | 35 |
| Idaho | 29 | Connecticut | 36 |
| Indiana | 29 | Rhode Island | 38 |
| Minnesota | 29 | Texas | 38 |
| New York | 29 | Hawaii | 41 |
| Oklahoma | 29 | South Carolina | 41 |
| Tennessee | 29 | North Dakota | 42 |
| Alabama | 30 | Montana | 44 |
| Delaware | 30 | ||
question 8
Which state(s) in the list below is a lower outlier? In other words, which has an unusually low percentage of drivers involved in fatal crashes who were impaired by alcohol? Choose all that apply.
a) Kentucky
b) Kansas
c) Utah
d) Alaska
question 9
Which of the following states have unusually high percentages of drivers involved in fatal crashes who were impaired by alcohol?
a) Texas, South Carolina, Montana
b) Montana, North Dakota, South Carolina, Hawaii
c) Montana, North Dakota, South Carolina
d) Texas, South Carolina, Montana, Rhode Island
question 10
Without computing the mean of the percentage of drivers involved in fatal crashes who were impaired by alcohol, make a prediction about whether the mean and median will be very different or fairly similar.
Now, let’s use technology to explore the dataset.
Go to the Describing and Exploring Quantitative Variables tool at https://dcmathpathways.shinyapps.io/EDA_quantitative/.
Step 1) Select the Single Group tab.
Step 2) Locate the dropdown under Enter Data and select From Textbook.
Step 3) Locate the drop-down menu under Dataset and select Bad Drivers (alcohol).
Step 4) Use the tool to compute the mean percentage of drivers involved in fatal collisions who were alcohol-impaired.
question 11
Which of the following describes your findings?
a) The mean is much higher than the median.
b) The median is much higher than the mean.
c) The mean and the median are about the same.
Identifying the Shape of a Distribution from a Boxplot
question 12
Just as histograms and dotplots can tell us about the distribution of a quantitative variable, so can a boxplot. For each boxplot below, choose the description that matches the shape of the data’s distribution. (Note that boxplots can be oriented vertically, as we saw previously, or horizontally, as we see below.)
| Boxplot | Distribution |
 |
a) left skewed
b) symmetric c) right skewed include dropdown options similar to Question 10 in WTK 4C |
 |
a) left skewed
b) symmetric c) right skewed include dropdown options similar to Question 10 in WTK 4C |
 |
a) left skewed
b) symmetric c) right skewed include dropdown options similar to Question 10 in WTK 4C |
Summary
In this section, you’ve learned about boxplots: how to calculate the five-number summary, how to read these numbers from a boxplot, and how to identify outliers in a dataset using the interquartile range. Let’s summarize where these skills showed up in the material.
- In Questions 1 and 7, you identified the features of a boxplot.
- In Questions 2 – 4, you interpreted the features of a boxplot.
- In Questions 5, 6, 8, and 9, you identified outliers in a dataset.
- In Questions 10 – 12, you related the boxplot of a quantitative variable to its distribution.
Being able to calculate and identify features of a boxplot and relate the boxplot and distribution of a quantitative variable are necessary statistical skills and will be used in the next activity. If you feel comfortable with these skills, please move on!
- Chalabi, M. (2014, October 24). Dear Mona, which state has the worst driver? FiveThirtyEight. https://fivethirtyeight.com/features/which-state-has-the-worst-drivers/ ↵
