goals for this section
After completing this section, you should feel comfortable performing these skills.
- Identify Quantitative Variables in a Dataset
- Identify graphical displays appropriate for visualizing quantitative data distributions.
- Use a data analysis tool to create a histogram of quantitative data.
- Read and interpret a histogram.
- Explain how the bin width affects a histogram.
- Use a data analysis tool to create a dotplot of quantitative data.
- Read and interpret a dotplot.
- Determine if a population and sample are appropriate to draw conclusions about a larger population.
Click on a skill above to jump to its location in this section.
In the next activity, you will need to identify quantitative variables, make plots of the distributions of quantitative variables, distinguish between a population and a sample, and explain limitations of analyses based on sample data. In this section, you’ll prepare for the activity by exploring the types of displays used to visualize quantitative variables.
Quantitative Variables
You learned to distinguish the difference between categorical and quantitative variables in section 1C, and you learned to identify and display distributions of categorical variables in the previous two sections, Displaying Categorical Data: 3A and Applications of Bar Graphs: 3B. Before we turn our attention to a thorough study of quantitative variables, take a moment to refresh your knowledge in the recall boxes below.
Recall
What is the distinguishing feature of a quantitative variable? That, how can we tell a quantitative variable apart from a categorical variable?
Core Skill:
We will explore quantitative displays later in this section. In the meantime, can you recall which graphs and charts are appropriate for displaying the distribution of a categorical variable?
Core skill:
Interactive Example
Which are the quantitative variables in the list below?
Salary, eye color, zip code, number of children in household, height, income level
In short, quantitative variables have numerical meaning. They are numbers that come with labels attached; 30 years, 82 points, 15,000 dollars, 3 speeding tickets are all examples of quantitative data observations. We can sum them up, take their average, and identify the minimum and maximum values.
Now it’s your turn to practice what you know using a real dataset. Read the example and description of the dataset and its variables below, then answer the questions that follow.
Identify Quantitative Variables in a Dataset
Let’s say we are interested in the ages of film actors who have won the highest professional accolades. Do they tend to be younger or older when they win a big award? We can use a dataset containing the ages of performers (a quantitative variable) at the time of receiving an award. While we won’t be able to draw conclusions about why the award recipients might tend to be younger or older, we can use a visual display to see if an interesting tendency emerges.
To investigate, we’ll ask the question, How old are the winners of the Best Actress and Best Actor awards at the Academy Awards (more commonly known as “the Oscars”)?
To answer this question, we will use data on “Best Actress/Actor” for the 184 winners from 1929 to 2018.[1] The table below shows the first five observations.
| Best Actress/Actor Winners from 1929 to 2018 |
|||||||||
| oscar_no | oscar_yr | award | name | movie | age | birth_pl | birth_mo | birth_d | birth_y |
| 1 | 1929 | Best actress | Janet Gaynor | 7th Heaven | 22 | Pennsylvania | 10 | 6 | 1906 |
| 2 | 1930 | Best actress | Mary Pickford | Coquette | 37 | Canada | 4 | 8 | 1892 |
| 3 | 1931 | Best actress | Norma Shearer | The Divorcee | 28 | Canada | 8 | 10 | 1902 |
| 4 | 1932 | Best actress | Marie Dressler | Min and Bill | 63 | Canada | 11 | 9 | 1868 |
| 5 | 1933 | Best actress | Helen Hayes | The Sin of Madelon Claudet | 32 | Washington DC | 10 | 10 | 1900 |
The following is the data dictionary for the variables in the table:
- oscar_no:Oscar ceremony number
- oscar_yr: Year of the Oscar ceremony
- award: Best Actress or Best Actor
- name: Name of award recipient
- movie: Name of movie
- age: Age of award recipient
- birth_pl: Birth place of award recipient
- birth_mo: Birth month of award recipient
- birth_d: Birth day of award recipient
- birth_y: Birth year of award recipient
quantitative versus categorical variables
[Insert a short video ( < 30 seconds) introducing the features of quantitative variables vs categorical in a data table or data dictionary (this extends the understanding obtained in 1C of identifying them from a list of words. The confusing variables in the data dictionary above include oscar_yr and birth_mo, which will appear to be numerical to students.]
question 1
Some of the variables in the data are listed below. Which variable is quantitative? There may be more than one correct answer.
- oscar_no
- birth_mo
- award
- age
Quantitative Displays
Earlier, you learned which kinds of graphs make good visualizations for categorical data. Just as certain graphs are useful for displaying data across categories (pie chart, bar graph, side-by-side and stacked bar graphs), others are especially well suited to quantitative data distributions. Categorical displays won’t work for quantitative data and vice-versa.
Identify graphical displays appropriate for visualizing quantitative data distributions.
In the future, you may need to choose a display based on the type of data distribution you have, so it is important to know which display works for the type of data you have. Answer the following question using what you have already learned about categorical data.
question 2
Which graphical display is NOT appropriate for visualizing the distribution of a quantitative variable? There may be more than one correct answer.
- Histogram
- Bar chart
- Dotplot
- Pie chart
We know that pie charts and bar charts (and side-by-side and stacked bar charts) are used to display categorical distributions. Histograms and dotplots are appropriate for displaying quantitative data.
- Dotplots display how many individual observations there are of each value observed. Each observation in the dataset appears as its own dot on the graph. A large number of observations could overwhelm the display so dotplots work well when the dataset is small.
- Histograms are good choices for displaying datasets that have a large number of observations since they group observations into equal-size “bins.” The bins can include any interval of values desired, so a histogram will not be overwhelmed by a large number of observations in a data set.
question 3
Which graphical display would be most appropriate for visualizing the distribution of a quantitative variable with a large number of observations?
- Pie chart
- Dotplot
- Histogram
- Side-by-side bar graph
Hint
Histograms
We’ve seen that a histogram is a graphical display used to visualize the distribution of a quantitative variable, and we know that it is a good choice to use when there are a large number of observations in the dataset, which is why histograms are commonly used for quantitative distributions. Let’s take a closer look at how a histogram is created before using the tool to create one ourselves.
creating a histogram
[Perspective Video – a 3-instructors video demonstrating how to create a histogram for a variable from a dataset, covering the features of a histogram, especially including binwidth and endpoints]
We can use the “Best Actress/Actor” data table as a resource to learn more about the features of a histogram. Below, see a histogram of the variable age from the dataset.
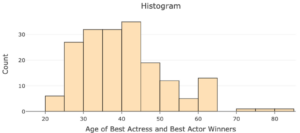
Similar to a bar graph, the height of each bar shows the number of observations within each “bin” (these would be the categories in the bar graph). A bin is a range of values that the quantitative variable can take. For example, the first bin on the histogram above is [20 , 25). The height of this bar shows there are six actors or actresses with ages that fall in this bin.
A bin can be defined by its end points, the smallest and largest values of the quantitative variable represented in the bin. For the first bin [20 , 25), the end points are 20 and 25. The notation [20 , 25) means this bin includes observations with ages that are at least 20 and less than 25.
Questions 4 and 5 below will help further understand the bins of a histogram.
question 4
The ages of four Academy Award winners are below. Which of the following would be included in the bin [35 , 40)? There may be more than one correct answer.
- 35
- 38
- 39
- 40
question 5
The bin width is the difference in the end points. What is the bin width for this histogram?
Using a Data Analysis Tool to Create Histograms
Go to the Describing and Exploring Quantitative Variables tool at https://istats.shinyapps.io/EDA_quantitative/ and create a histogram for the distribution of age of the 184 Best Actress/Actor winners, following the steps below:
Step 1) Select the Single Group tab
Step 2) Locate the dropdown under Enter Data and select Your Own.
Step 3) For Do you have: select Individual Observations.
Step 4) In the Name of Variable box, type “Age“.
Step 5) Download the Oscars_Age spreadsheet and copy and paste the age data.
Step 6) Locate Choose Type of Plot and choose Histogram. Unselect any other types.
Step 7) Select Binwidth For Histogram to 5.
question 6
Read and interpret a histogram.
reading and interpreting histograms
[Worked Example — a 3-instructors worked example of reading and interpreting histograms with different binwidths — showing which binwidth seems “better” for answering certain questions about the distribution. )
Use the histogram you created to answer the following questions. (Hint: Hover over the histogram to get the exact height of each bar.)
question 7
How many actors were 20–24 years old when they won the award?
question 8
How many actors were 50–69 years old when they won the award?
question 9
What proportion of actors were 35–39 years old when they won the award? Round your answer to the nearest hundredth.
question 10
True or False: Suppose we randomly select an actor from the dataset. It is more likely that person was 60–64 years old when they won than 20–24 years old.
Effects of Bin Widths on Histograms
Using a different bin width for the histogram can change the features of the distribution we are able to see from the graphical display.
question 11
question 12
question 13
Which bin width (1, 5, or 20) results in a histogram that’s most useful for summarizing the distribution of age? Explain.
Dotplots
In a previous activity, you created a dotplot, a graphical display for quantitative data where each dot represents an single observation in a dataset. Dotplots are useful for visualizing distributions when the dataset is small.
There aren’t as many features to understand about a dotplot as there are with histograms. We’ll begin our exploration by creating one with the tool, which we will read and interpret.
Using a Data Analysis Tool to Create Dotplots
We’ll use a dotplot to visualize the same distribution of age of Best Actress/Actor winners.
With the same tool open that you used to create the histogram (or by following Steps 1 – 4 above), check the “Dotplot” box. Use dotsize = 1 and bin width = 1.
question 14
Read and interpret a dotplot.
question 15
Use the dotplot to determine which of the following statements is true. There may be more than one correct answer.
- It is uncommon for an actor over 70 years old to win the Best Actress/Actor award.
- Ten actors were 29 years old when they won the award.
- There were more actors who were 26 years old when they won than actors who were 38 years old when they won.
- Each dot on the plot represents a Best Actress/Actor winner.
- There were more winners in their 50s (50–59) than in their 60s (60–69).
Looking Ahead: Drawing Conclusions about Larger Populations
You saw a brief introduction to statistical inference earlier in the course, the process of making inferences about a population based on data collected on a sample from that population. We’ll study it in greater detail later, but it will be helpful to consider the idea of a representative sample from time to time along the way. You learned in section 2A that a sampling method is considered biased if it has a tendency to produce samples that are not representative of the population. When that happens, we cannot generalize our results to the population and can only make statements about the sample itself.
Recall
Core skill:
The question below will help you to develop your understanding of when you can use the results of an analysis to make statements about some larger population of which your sample is a subset.
To answer this question, consider that the dataset we’ve explored in this section, Best Actress/Actor” for the 184 winners from 1929 to 2018, includes observations on people who won this award over an 89 year span. The people about whom data was collected are also members of the set of all Oscar winners in the timespan, which is itself a subset of all Hollywood film actors.
question 16
Suppose someone is doing an analysis on Hollywood film actors. Should they use the results from the analysis in this activity to draw conclusions about the ages of Hollywood film actors? Explain.
In the next activity, we’ll continue this theme by talking about the runtime of well-loved movies. Get ready by thinking about those movies you could watch over and over. Look up the “runtime” (length of the movie in minutes) of your favorite movies to compare with others in the next activity.
- Navigate to https://www.imdb.com/.
- Type your favorite movie in the search bar. Select the title.
- Convert the runtime into minutes and record that value.
For example, if your favorite movie is Happy Gilmore, the runtime is listed as one hour, 32 minutes. Therefore, the runtime that you will record is 92 minutes.
question 17
The next activity will be about favorite movies. Record the “runtime” (length of the movie in minutes) of your favorite movie here.
Summary
In this section, you’ve had a chance to practice the tasks that will be essential to forming deeper connections in the next activity. This is a good time to sum it all up before moving on.
- In Questions 1, 2, and 3, you identified quantitative variables and the plots used to visualize their distributions.
- In Questions 4, 5, 6, and 14, you used technology to make a plot of the distribution of a quantitative variable.
- In Questions 7 – 10, you used a histogram to describe a distribution.
- In Questions 11, 12, and 13 you explored how bin width affects a histogram.
- In Question 15, you used a dotplot to describe a distribution.
- In Question 16, you identified the population and the sample.
- In Question 16, you considered limitations on the scope of analysis based on the sample data.
This section gave you an opportunity to see that dotplots and histograms are good ways to visualize quantitative data. You also received some practice manipulating the bin width of a histogram to see how it affected the information displayed. Finally, you were needed to differentiate between the population and the sample to discuss possible limitations on the scope of an analysis of sample data. If you feel comfortable with these ideas, please move on to the next activity in Forming Connections.
- Oscar winners, 1929 to 2018. (n.d.). OpenIntro. Retrieved from https://www.openintro.org/data/index.php?data=oscars ↵
