Learning Outcomes
- Calculate the range of a data set
- Calculate the standard deviation for a data set and determine its units
Reading with a pencil in hand
The topics on this page are technical and require careful computations. Be sure to write out the examples by hand. The practice will pay off at test time!
Range and Standard Deviation
Consider these three sets of quiz scores:
Section A: 5 5 5 5 5 5 5 5 5 5
Section B: 0 0 0 0 0 10 10 10 10 10
Section C: 4 4 4 5 5 5 5 6 6 6
All three of these sets of data have a mean of 5 and median of 5, yet the sets of scores are clearly quite different. In section A, everyone had the same score; in section B half the class got no points and the other half got a perfect score, assuming this was a 10-point quiz. Section C was not as consistent as section A, but not as widely varied as section B.
In addition to the mean and median, which are measures of the “typical” or “middle” value, we also need a measure of how “spread out” or varied each data set is.
There are several ways to measure this “spread” of the data. The first is the simplest and is called the range.
Range
The range is the difference between the maximum value and the minimum value of the data set.
example
Using the quiz scores from above,
For section A, the range is 0 since both maximum and minimum are 5 and 5 – 5 = 0
For section B, the range is 10 since 10 – 0 = 10
For section C, the range is 2 since 6 – 4 = 2
In the last example, the range seems to be revealing how spread out the data is. However, suppose we add a fourth section, Section D, with scores 0 5 5 5 5 5 5 5 5 10.
This section also has a mean and median of 5. The range is 10, yet this data set is quite different than Section B. To better illuminate the differences, we’ll have to turn to a more sophisticated measure of variation (spread).
The range of this example is explained in the following video.
Standard deviation
The standard deviation is a measure of variation based on measuring how far each data value deviates, or is different, from the mean. A few important characteristics:
- Standard deviation is always positive. Standard deviation will be zero if all the data values are equal, and will get larger as the data spreads out.
- Standard deviation has the same units as the original data.
- Standard deviation, like the mean, can be highly influenced by outliers.
recall properties of square roots
You’ll need these properties for the information that follows.
[latex]-a^{2}=-\left(a\ast a\right)=-a^2[/latex]
[latex]\left(-a\right)^{2}=\left(-a\right)\ast \left(-a\right)=a^{2}[/latex]
Using the data from section D, we could compute for each data value the difference between the data value and the mean:
| data value | deviation: data value – mean |
|---|---|
| 0 | 0-5 = -5 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 10 | 10-5 = 5 |
We would like to get an idea of the “average” deviation from the mean, but if we find the average of the values in the second column the negative and positive values cancel each other out (this will always happen), so to prevent this we square every value in the second column:
| data value | deviation: data value – mean | deviation squared |
|---|---|---|
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 10 | 10-5 = 5 | (5)2 = 25 |
We then add the squared deviations up to get 25 + 0 + 0 + 0 + 0 + 0 + 0 + 0 + 0 + 25 = 50. Ordinarily we would then divide by the number of scores, n, (in this case, 10) to find the mean of the deviations. But we only do this if the data set represents a population; if the data set represents a sample (as it almost always does), we instead divide by n – 1 (in this case, 10 – 1 = 9).[1]
So in our example, we would have 50/10 = 5 if section D represents a population and 50/9 = about 5.56 if section D represents a sample. These values (5 and 5.56) are called, respectively, the population variance and the sample variance for section D.
Variance can be a useful statistical concept, but note that the units of variance in this instance would be points-squared since we squared all of the deviations. What are points-squared? Good question. We would rather deal with the units we started with (points in this case), so to convert back we take the square root and get:
[latex]\begin{align}&\text{population standard deviation}=\sqrt{\frac{50}{10}}=\sqrt{5}\approx2.2\\&\text{or}\\&\text{sample standard deviation}=\sqrt{\frac{50}{9}}\approx2.4\\\end{align}[/latex]
If we are unsure whether the data set is a sample or a population, we will usually assume it is a sample, and we will round answers to one more decimal place than the original data, as we have done above.
To compute standard deviation
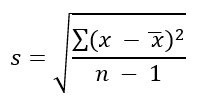
- Find the deviation of each data from the mean. In other words, subtract the mean from the data value.
- Square each deviation.
- Add the squared deviations.
- Divide by n, the number of data values, if the data represents a whole population; divide by n – 1 if the data is from a sample.
- Compute the square root of the result.
example
Computing the standard deviation for Section B above, we first calculate that the mean is 5. Using a table can help keep track of your computations for the standard deviation:
| data value | deviation: data value – mean | deviation squared |
|---|---|---|
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 10 | 10-5 = 5 | (5)2 = 25 |
| 10 | 10-5 = 5 | (5)2 = 25 |
| 10 | 10-5 = 5 | (5)2 = 25 |
| 10 | 10-5 = 5 | (5)2 = 25 |
| 10 | 10-5 = 5 | (5)2 = 25 |
Assuming this data represents a population, we will add the squared deviations, divide by 10, the number of data values, and compute the square root:
[latex]\sqrt{\frac{25+25+25+25+25+25+25+25+25+25}{10}}=\sqrt{\frac{250}{10}}=5[/latex]
Notice that the standard deviation of this data set is much larger than that of section D since the data in this set is more spread out.
For comparison, the standard deviations of all four sections are:
| Section A: 5 5 5 5 5 5 5 5 5 5 | Standard deviation: 0 |
| Section B: 0 0 0 0 0 10 10 10 10 10 | Standard deviation: 5 |
| Section C: 4 4 4 5 5 5 5 6 6 6 | Standard deviation: 0.8 |
| Section D: 0 5 5 5 5 5 5 5 5 10 | Standard deviation: 2.2 |
See the following video for more about calculating the standard deviation in this example.
Try It
The price of a jar of peanut butter at 5 stores was $3.29, $3.59, $3.79, $3.75, and $3.99. Find the standard deviation of the prices.
To compute standard deviation for data in a frequency table

- Find the deviation of each data from the mean. In other words, subtract the mean from the data value.
- Square each deviation.
- Multiply the frequency and corresponding squared deviation.
- Add the products.
- Divide by n, the number of data values, if the data represents a whole population; divide by n – 1 if the data is from a sample.
- Compute the square root of the result.
Candela Citations
- Revision and Adaptation. Provided by: Lumen Learning. License: CC BY: Attribution
- Measures of Variation. Authored by: David Lippman. Located at: http://www.opentextbookstore.com/mathinsociety/. Project: Math in Society. License: CC BY-SA: Attribution-ShareAlike
- Butte aux canons. Authored by: Alexandre Duret-Lutz. Located at: https://flic.kr/p/stgEf. License: CC BY-SA: Attribution-ShareAlike
- Finding range of a data set. Authored by: OCLPhase2's channel. Located at: https://youtu.be/b3ofWalrHgQ. License: CC BY: Attribution
- Computing standard deviation 1. Authored by: OCLPhase2's channel. Located at: https://youtu.be/wS8z90f04OU. License: CC BY: Attribution
- Five number summary 1. Authored by: OCLPhase2's channel. Located at: https://youtu.be/00iQvPOOUu4. License: CC BY: Attribution
- Five number summary 2. Authored by: OCLPhase2's channel. Located at: https://youtu.be/x73G2Nep05g. License: CC BY: Attribution
- Five number summary 3. Authored by: OCLPhase2's channel. Located at: https://youtu.be/uifLbZKPUDU. License: CC BY: Attribution
- Five number summary from a frequency table. Authored by: OCLPhase2's channel. Located at: https://youtu.be/ECOeeDrUxpo. License: CC BY: Attribution
- Creating a boxplot. Authored by: OCLPhase2's channel. Located at: https://youtu.be/s4SPGFlMBMU. License: CC BY: Attribution
- Comparing boxplots. Authored by: OCLPhase2's channel. Located at: https://youtu.be/eUkgf-2NVO8. License: CC BY: Attribution
- The reason we do this is highly technical, but we can see how it might be useful by considering the case of a small sample from a population that contains an outlier, which would increase the average deviation: the outlier very likely won't be included in the sample, so the mean deviation of the sample would underestimate the mean deviation of the population; thus we divide by a slightly smaller number to get a slightly bigger average deviation. ↵
