Learning Objectives
- (9.1.1) – Define and evaluate principal square roots
- Square roots
- Cube roots
- (9.1.2) – Define and evaluate nth roots
- (9.1.3) – Estimate roots that are not perfect
(9.1.1) – Define and evaluate principal square roots
Did you know that you can take the 6th root of a number? You have probably heard of a square root, written [latex]\sqrt{}[/latex], but you can also take a third, fourth and even a 5,000th root (if you really had to). In this lesson we will learn how a square root is defined and then we will build on that to form an understanding of nth roots. We will use factoring and rules for exponents to simplify mathematical expressions that contain roots.
The most common root is the square root. First, we will define what square roots are, and how you find the square root of a number. Then we will apply similar ideas to define and evaluate nth roots.
Roots are the inverse of exponents, much like multiplication is the inverse of division. Recall how exponents are defined, and written; with an exponent, as words, and as repeated multiplication.
Exponent: [latex]{{3}^{2}}[/latex], [latex]{{4}^{5}}[/latex], [latex]{{x}^{3}}[/latex], [latex]{{x}^{\text{n}}}[/latex]
Name: “Three squared” or “Three to the second power”, “Four to the fifth power”, “x cubed”, “x to the nth power”
Repeated Multiplication: [latex]3\cdot 3[/latex], [latex]4\cdot 4\cdot 4\cdot 4\cdot 4[/latex], [latex]x\cdot x\cdot x[/latex], [latex]\underbrace{x\cdot x\cdot x...\cdot x}_{n\text{ times}}[/latex].
Conversely, when you are trying to find the square root of a number (say, 25), you are trying to find a number that can be multiplied by itself to create that original number. In the case of 25, you can find that [latex]5\cdot5=25[/latex], so 5 must be the square root.
Square Roots
The symbol for the square root is called a radical symbol and looks like this: [latex]\sqrt{\,\,\,}[/latex]. The expression [latex]\sqrt{25}[/latex] is read “the square root of twenty-five” or “radical twenty-five.” The number that is written under the radical symbol is called the radicand.
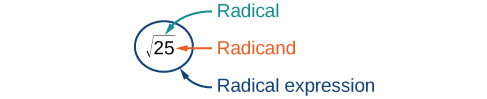
The following table shows different radicals and their equivalent written and simplified forms.
| Radical | Name | Simplified Form |
|---|---|---|
| [latex]\sqrt{36}[/latex] | “Square root of thirty-six”
“Radical thirty-six” |
[latex]\sqrt{36}=\sqrt{6\cdot 6}=6[/latex] |
| [latex]\sqrt{100}[/latex] | “Square root of one hundred”
“Radical one hundred” |
[latex]\sqrt{100}=\sqrt{10\cdot 10}=10[/latex] |
| [latex]\sqrt{225}[/latex] | “Square root of two hundred twenty-five”
“Radical two hundred twenty-five” |
[latex]\sqrt{225}=\sqrt{15\cdot 15}=15[/latex] |
Consider [latex]\sqrt{25}[/latex] again. You may realize that there is another value that, when multiplied by itself, also results in 25. That number is [latex]−5[/latex].
[latex]\begin{array}{r}5\cdot 5=25\\-5\cdot -5=25\end{array}[/latex]
By definition, the square root symbol always means to find the positive root, called the principal root. So while [latex]5\cdot5[/latex] and [latex]−5\cdot−5[/latex] both equal 25, only 5 is the principal root. You should also know that zero is special because it has only one square root: itself (since [latex]0\cdot0=0[/latex]).
In our first example we will show you how to use radical notation to evaluate principal square roots.
Example
Find the principal root of each expression.
- [latex]\sqrt{100}[/latex]
- [latex]\sqrt{16}[/latex]
- [latex]\sqrt{25+144}[/latex]
- [latex]\sqrt{49}-\sqrt{81}[/latex]
- [latex]-\sqrt{81}[/latex]
- [latex]\sqrt{-9}[/latex]
In the following video we present more examples of how to find a principle square root.
The last example we showed leads to an important characteristic of square roots. You can only take the square root of values that are nonnegative.
Domain of a Square Root
[latex]\sqrt{-a}[/latex] is not defined for all real numbers, a. Therefore, [latex]\sqrt{a}[/latex] is defined for [latex]a\ge0[/latex]
Think About It
Does [latex]\sqrt{25}=\pm 5[/latex]? Write your ideas and a sentence to defend them in the box below before you look at the answer.
Cube Roots
We know that [latex]5^2=25, \text{ and }\sqrt{25}=5[/latex] but what if we want to "undo" [latex]5^3=125, \text{ or }5^4=625[/latex]? We can use higher order roots to answer these questions.
Suppose we know that [latex]{a}^{3}=8[/latex]. We want to find what number raised to the 3rd power is equal to 8. Since [latex]{2}^{3}=8[/latex], we say that 2 is the cube root of 8. In the next example we will evaluate the cube roots of some perfect cubes.
Example
Evaluate the following:
- [latex]\sqrt[3]{125}[/latex]
- [latex]\sqrt[3]{-8}[/latex]
- [latex]\sqrt[3]{27}[/latex]
As we saw in the last example,there is one interesting fact about cube roots that is not true of square roots. Negative numbers can’t have real number square roots, but negative numbers can have real number cube roots! What is the cube root of [latex]−8[/latex]? [latex]\sqrt[3]{-8}=-2[/latex] because [latex](-2)\cdot (-2)\cdot (-2)=-8[/latex]. Remember, when you are multiplying an odd number of negative numbers, the result is negative! Consider [latex]\sqrt[3]{{{(-1)}^{3}}}=-1[/latex].
In the following video we show more examples of finding a cube root.
(9.1.2) - Define and evaluate nth roots
The cube root of a number is written with a small number 3, called the index, just outside and above the radical symbol. It looks like [latex]\displaystyle {\,}^3\hspace{-0.1in}\sqrt{\,\,\,}[/latex]. This little 3 distinguishes cube roots from square roots which are written without a small number outside and above the radical symbol.
We can apply the same idea to any exponent and it's corresponding root. The [latex]n^{th}[/latex] root of [latex]a[/latex] is a number that, when raised to the [latex]n^{th}[/latex] power, gives [latex]a[/latex]. For example, [latex]3[/latex] is the 5th root of [latex]243[/latex] because [latex]{\left(3\right)}^{5}=243[/latex]. If [latex]a[/latex] is a real number with at least one [latex]n^{th}[/latex] root, then the principal [latex]\boldsymbol{n^{th}}[/latex] root of [latex]a[/latex] is the number with the same sign as [latex]a[/latex] that, when raised to the nth power, equals [latex]a[/latex].
The principal [latex]n^{th}[/latex] root of [latex]a[/latex] is written as [latex]\sqrt[n]{a}[/latex], where [latex]n[/latex] is a positive integer greater than or equal to 2. In the radical expression, [latex]n[/latex] is called the index of the radical.
Definition: Principal [latex]n^{th}[/latex] Root
If [latex]a[/latex] is a real number with at least one [latex]n^{th}[/latex] root, then the principal [latex]\boldsymbol{n^{th}}[/latex] root of [latex]a[/latex], written as [latex]\sqrt[n]{a}[/latex], is the number with the same sign as [latex]a[/latex] that, when raised to the [latex]n^{th}[/latex] power, equals [latex]a[/latex]. The index of the radical is [latex]n[/latex].
Example
Evaluate each of the following:
- [latex]\sqrt[5]{-32}[/latex]
- [latex]\sqrt[4]{81}[/latex]
- [latex]\sqrt[8]{-1}[/latex]
In the following video we show more examples of how to evaluate and nth root.
You can find the odd root of a negative number, but you cannot find the even root of a negative number. This means you can evaluate the radicals [latex]\sqrt[3]{-81},\ \sqrt[5]{-64}[/latex], and [latex]\sqrt[7]{-2187}[/latex], but you cannot evaluate the radicals [latex]\sqrt[{}]{-100},\ \sqrt[4]{-16}[/latex], or [latex]\sqrt[6]{-2,500}[/latex].
(9.1.3) - Estimate roots that are not perfect
An approach to handling roots that are not perfect (squares, cubes, etc.) is to approximate them by comparing the values to perfect squares, cubes, or nth roots. Suppose you wanted to know the square root of 17. Let’s look at how you might approximate it.
Example
Estimate. [latex]\sqrt{17}[/latex]
This approximation is pretty close. If you kept using this trial and error strategy you could continue to find the square root to the thousandths, ten-thousandths, and hundred-thousandths places, but eventually it would become too tedious to do by hand.
For this reason, when you need to find a more precise approximation of a square root, you should use a calculator. Most calculators have a square root key [latex](\sqrt{{\,\,\,}})[/latex] that will give you the square root approximation quickly. On a simple 4-function calculator, you would likely key in the number that you want to take the square root of and then press the square root key.
Try to find [latex]\sqrt{17}[/latex] using your calculator. Note that you will not be able to get an “exact” answer because [latex]\sqrt{17}[/latex] is an irrational number, a number that cannot be expressed as a fraction, and the decimal never terminates or repeats. To nine decimal positions, [latex]\sqrt{17}[/latex] is approximated as 4.123105626. A calculator can save a lot of time and yield a more precise square root when you are dealing with numbers that aren’t perfect squares.
Example
Approximate [latex]\sqrt[3]{30}[/latex] and also find its value using a calculator.
The following video shows another example of how to estimate a square root.
Candela Citations
- Simplify a Variety of Square Expressions (Simplify Perfectly). Authored by: James Sousa (Mathispower4u.com) for Lumen Learning. Located at: https://youtu.be/2cWAkmJoaDQ. License: CC BY: Attribution
- Simplify Cube Roots (Perfect Cube Radicands). Authored by: James Sousa (Mathispower4u.com) for Lumen Learning. Located at: https://youtu.be/9Nh-Ggd2VJo. License: CC BY: Attribution
- Approximate a Square Root to Two Decimal Places Using Trial and Error. Authored by: James Sousa (Mathispower4u.com) for Lumen Learning. Located at: https://youtu.be/iNfalyW7olk. License: CC BY: Attribution